Ensuring Data Integrity: ACID Compliance in Banking Ledger Systems
Ensuring ACID compliance is critical for maintaining data integrity and reliability in financial transactions. This in-depth guide explores how Atomicity, Consistency, Isolation, and Durability (ACID) principles apply to a banking ledger system, preventing data corruption, race conditions, and transaction failures. Learn best practices for SQL database design, concurrency control, and high-availability deployments to build a secure and scalable financial system

1. Introduction
Overview of a Banking Ledger System
A banking ledger system is a core financial database that records transactions across accounts while ensuring accuracy, security, and compliance with financial regulations. Every banking operation, such as deposits, withdrawals, and transfers, must be precisely recorded to maintain financial integrity.
A banking ledger system is a structured database that records every financial transaction to maintain accurate balances. It prevents errors such as duplicate transactions, incorrect debits, and inconsistent account states.
A well-designed banking ledger system:
- Tracks account balances with real-time updates.
- Ensures transaction accuracy by enforcing database constraints.
- Provides audit trails for regulatory compliance.
- Prevents double spending and race conditions through robust transaction management.
Key Functionalities of a Banking Ledger System
- Account Management – Creating and maintaining user accounts.
- Transaction Processing – Recording deposits, withdrawals, and transfers.
- Balance Verification – Ensuring accurate account balances after each transaction.
- ACID-Compliant Transaction Handling – Guaranteeing reliability in transaction execution.
- Security and Compliance – Enforcing encryption, logging, and fraud detection.
A well-designed banking ledger system follows double-entry accounting, where each transaction impacts at least two accounts (e.g., debiting one and crediting another). This ensures accuracy and prevents discrepancies in financial records.
Importance of ACID Compliance in Financial Transactions
Financial transactions must be reliable and error-free, as even a minor inconsistency can lead to serious issues like incorrect balances, overdrafts, or even fraud. ACID compliance (Atomicity, Consistency, Isolation, Durability) is the foundation of a secure banking ledger system.
Without ACID compliance, banking systems can experience catastrophic failures:
- In 2012, a UK bank’s faulty transaction system led to thousands of duplicate withdrawals.
- A major credit card provider faced transaction inconsistencies due to improper isolation in concurrent transactions.
- Power failures in a non-ACID-compliant system once caused millions of dollars in lost transactions.
Without ACID compliance, a banking ledger system could face:
- Partial Transactions – Money could be withdrawn without updating the recipient’s account.
- Data Corruption – Simultaneous transactions could cause incorrect balances.
- System Failures – Power outages or crashes could result in incomplete or lost transactions.
Use STRICT constraints such as:
- FOREIGN KEYS to enforce account relationships.
- CHECK constraints to prevent negative balances.
- UNIQUE constraints to stop duplicate transactions. These ensure data integrity and prevent logical errors in your ledger system.
To prevent financial discrepancies, a banking system must execute transactions in a way that:
- Either fully completes or does nothing (Atomicity).
- Maintains logical consistency of all data changes (Consistency).
- Prevents interference from concurrent transactions (Isolation).
- Ensures committed transactions are permanently stored (Durability).
A banking ledger must be ACID-compliant to ensure trust, reliability, and security in financial institutions.
Imagine two customers withdrawing money from the same account at the same time.
Without transaction isolation, both could withdraw more than the available balance, causing an overdraft.
Solution: Databases enforce isolation levels (like SERIALIZABLE or REPEATABLE READ) to prevent race conditions and ensure accuracy.
Goals of This Guide
This guide will walk you through the process of designing and implementing a robust, ACID-compliant banking ledger system. You will learn:
- How to structure your database schema for financial transactions.
- The importance of ACID principles in transaction management.
- Concurrency control mechanisms to prevent race conditions.
- How to secure and optimize the banking ledger for high performance.
- Step-by-step implementation, from database setup to scaling in production.
By the end, you’ll have a fully functional banking ledger system that guarantees accuracy, reliability, and compliance with financial standards.
Section 2: Database Schema Design and ACID Compliance
Introduction
A well-designed database schema is the foundation of an ACID-compliant banking ledger system. It ensures data integrity, prevents anomalies, and enables efficient transaction processing. This section outlines the core tables, their relationships, and SQL implementation to enforce ACID properties.
Info: A normalized database schema helps eliminate redundancy and improve data integrity, which is essential for banking systems.
Core Database Tables
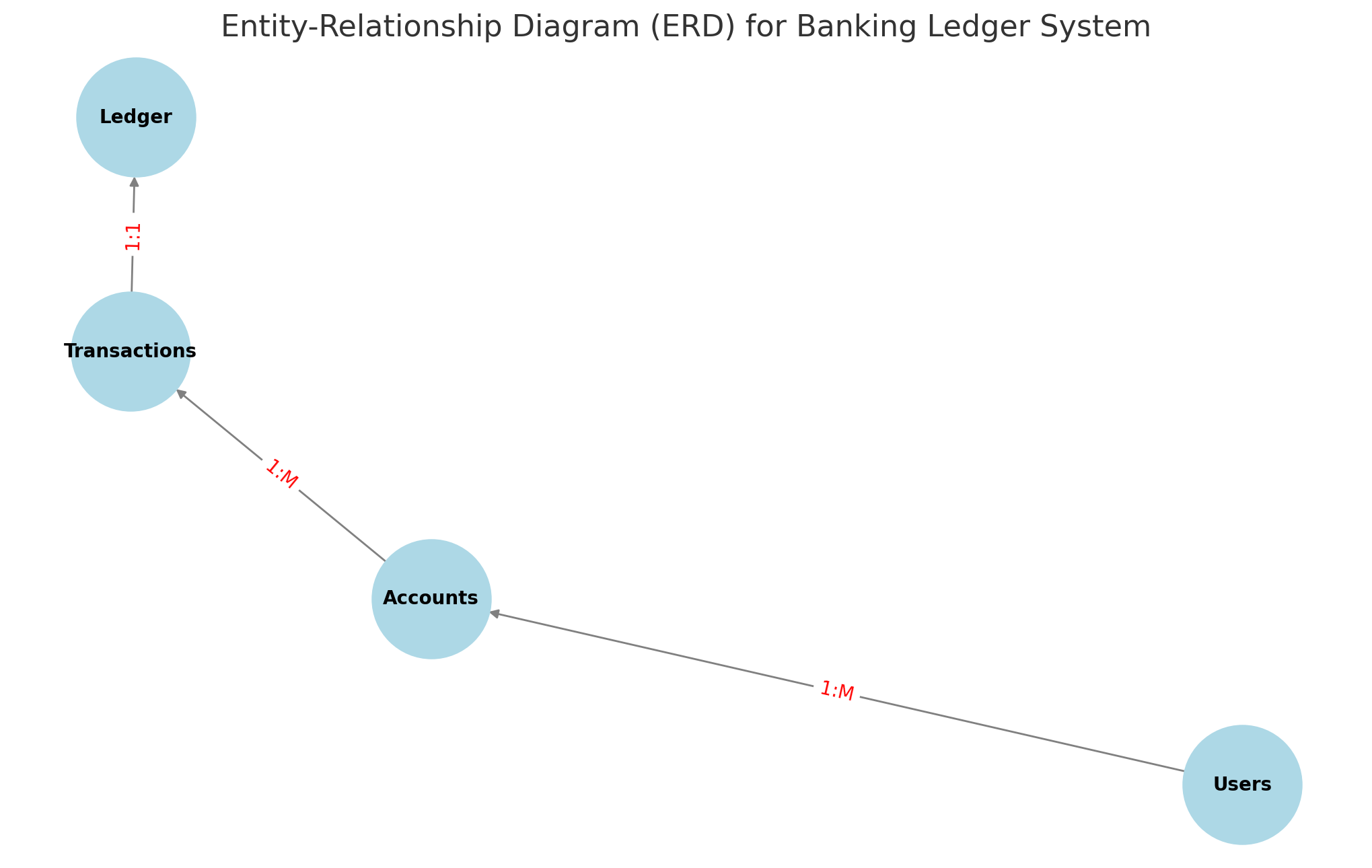
📌 Diagram: The Entity-Relationship Diagram (ERD) above visually represents the structure and relationships between Users, Accounts, Transactions, and the Ledger. It helps in understanding how data flows between different tables.
To build a robust banking ledger system, we define the following essential tables:
1. Users Table
Stores customer details and account holders.
1
2
3
4
5
6
CREATE TABLE Users (
user_id SERIAL PRIMARY KEY,
full_name VARCHAR(255) NOT NULL,
email VARCHAR(255) UNIQUE NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Info: Storing email as
UNIQUEensures that no two users can register with the same email, improving system integrity.
2. Accounts Table
Represents individual bank accounts.
1
2
3
4
5
6
7
CREATE TABLE Accounts (
account_id SERIAL PRIMARY KEY,
user_id INT REFERENCES Users(user_id) ON DELETE CASCADE,
account_type VARCHAR(50) NOT NULL CHECK (account_type IN ('Checking', 'Savings')),
balance DECIMAL(18,2) NOT NULL DEFAULT 0.00,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Tip: The
ON DELETE CASCADEensures that when a user is deleted, their associated accounts are also removed, maintaining referential integrity.
3. Transactions Table
Logs all financial transactions to maintain consistency.
1
2
3
4
5
6
7
CREATE TABLE Transactions (
transaction_id SERIAL PRIMARY KEY,
account_id INT REFERENCES Accounts(account_id) ON DELETE CASCADE,
transaction_type VARCHAR(50) NOT NULL CHECK (transaction_type IN ('Deposit', 'Withdrawal', 'Transfer')),
amount DECIMAL(18,2) NOT NULL CHECK (amount > 0),
transaction_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Info: Defining
transaction_typeas an ENUM-likeCHECKconstraint ensures that only valid transaction types are allowed, preventing invalid entries.
4. Ledger Table
Maintains a double-entry bookkeeping record.
1
2
3
4
5
6
7
8
CREATE TABLE Ledger (
ledger_id SERIAL PRIMARY KEY,
transaction_id INT REFERENCES Transactions(transaction_id) ON DELETE CASCADE,
debit_account INT REFERENCES Accounts(account_id),
credit_account INT REFERENCES Accounts(account_id),
amount DECIMAL(18,2) NOT NULL CHECK (amount > 0),
ledger_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Tip: The Ledger table ensures financial accountability by maintaining both debit and credit records for each transaction, supporting double-entry accounting principles.
Normalization & Constraints
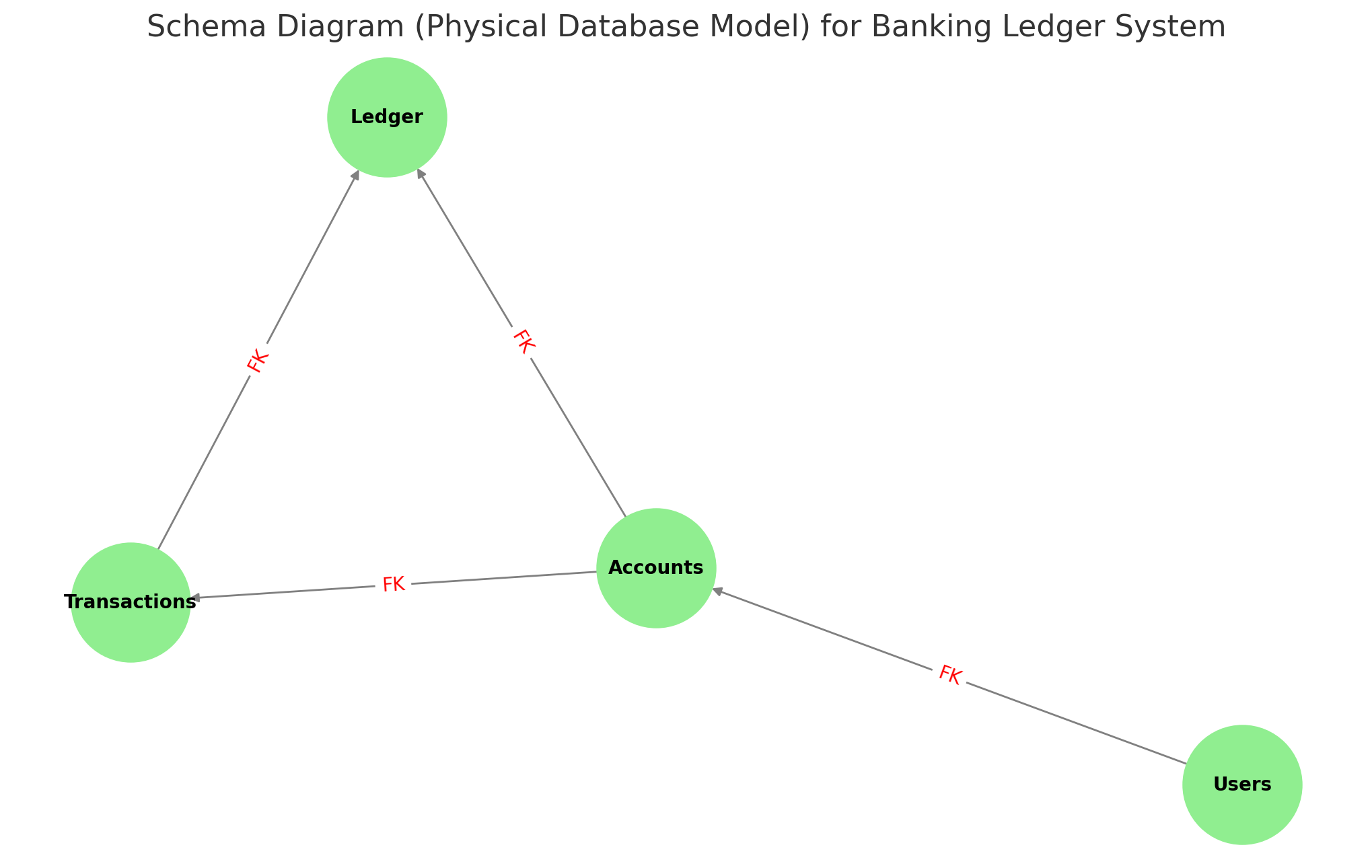
ℹ️ Diagram: The Schema Diagram (Physical Database Model) above details primary keys, foreign keys, and constraints for each table, ensuring data integrity and enforcing relationships.
To maintain data integrity and ACID compliance:
Normalization: The schema follows 3rd Normal Form (3NF), eliminating redundant data.
Primary Keys: Ensures unique identification of records.
Foreign Keys & Referential Integrity: Enforce valid relationships between entities.
Constraints:
CHECKensures valid values.ON DELETE CASCADEmaintains consistency on deletions.
Info: Using constraints like CHECK prevents invalid data entry, reducing errors and maintaining database consistency.
SQL Implementation of ACID Compliance
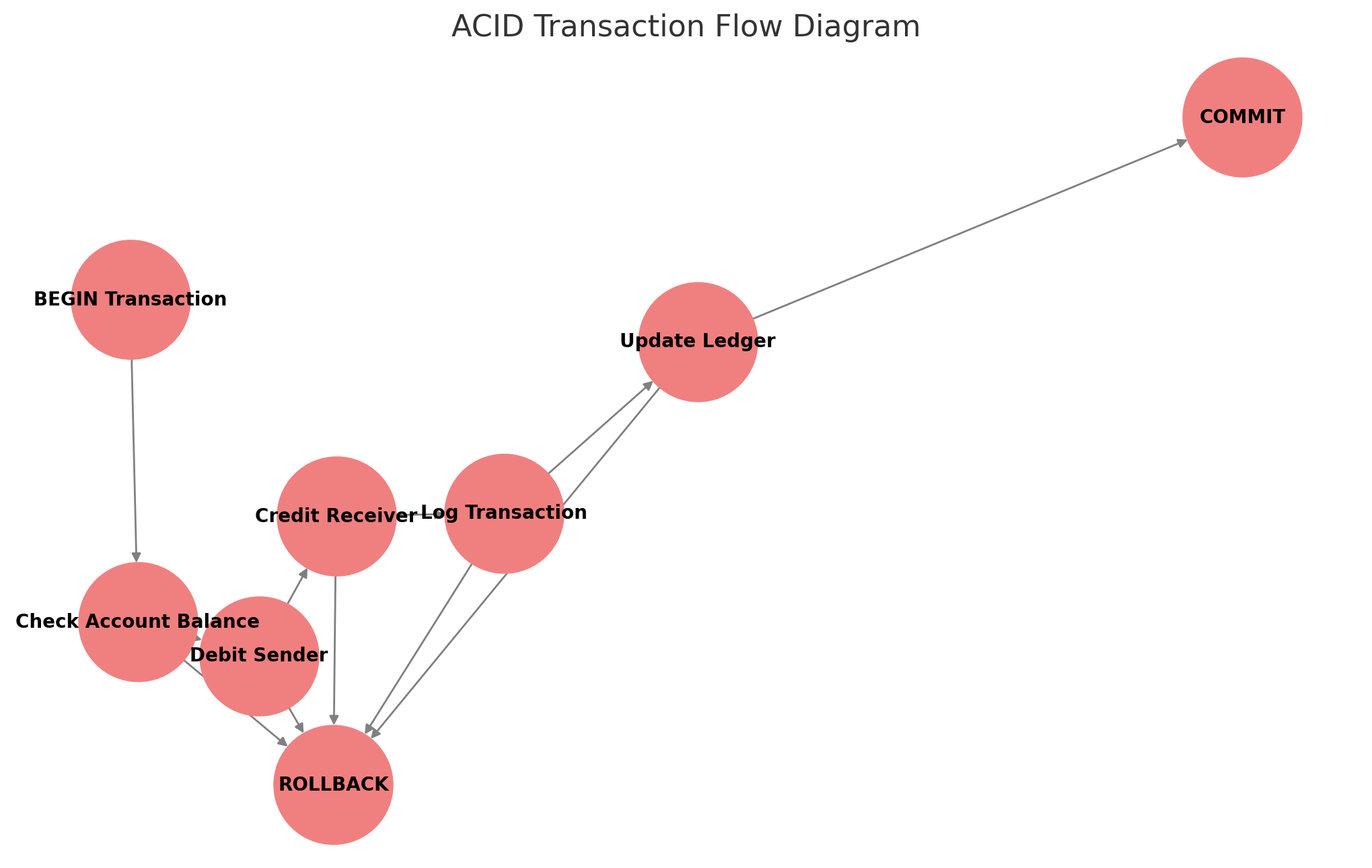
✅ Diagram: The ACID Transaction Flow Diagram above shows how a transaction ensures atomicity, consistency, isolation, and durability. If any step fails, the entire transaction is rolled back to maintain database integrity.
Transactions must be atomic, consistent, isolated, and durable. Here’s an example of a transaction-safe fund transfer:
1
2
3
4
5
6
7
8
9
10
11
12
13
BEGIN;
-- Deduct amount from sender's account
UPDATE Accounts SET balance = balance - 100.00 WHERE account_id = 1;
-- Add amount to receiver's account
UPDATE Accounts SET balance = balance + 100.00 WHERE account_id = 2;
-- Insert record into Transactions table
INSERT INTO Transactions (account_id, transaction_type, amount) VALUES (1, 'Transfer', 100.00), (2, 'Transfer', 100.00);
-- Commit transaction
COMMIT;
Tip: Using
BEGINandCOMMITensures atomicity—if any step fails, the entire transaction will not be applied.
Info: Should we implement a rollback mechanism in case of transaction failure? Consider adding
SAVEPOINTorROLLBACKfor error handling to prevent partial updates.
This ensures that if any step fails, the entire transaction rolls back, maintaining consistency and atomicity.
Conclusion
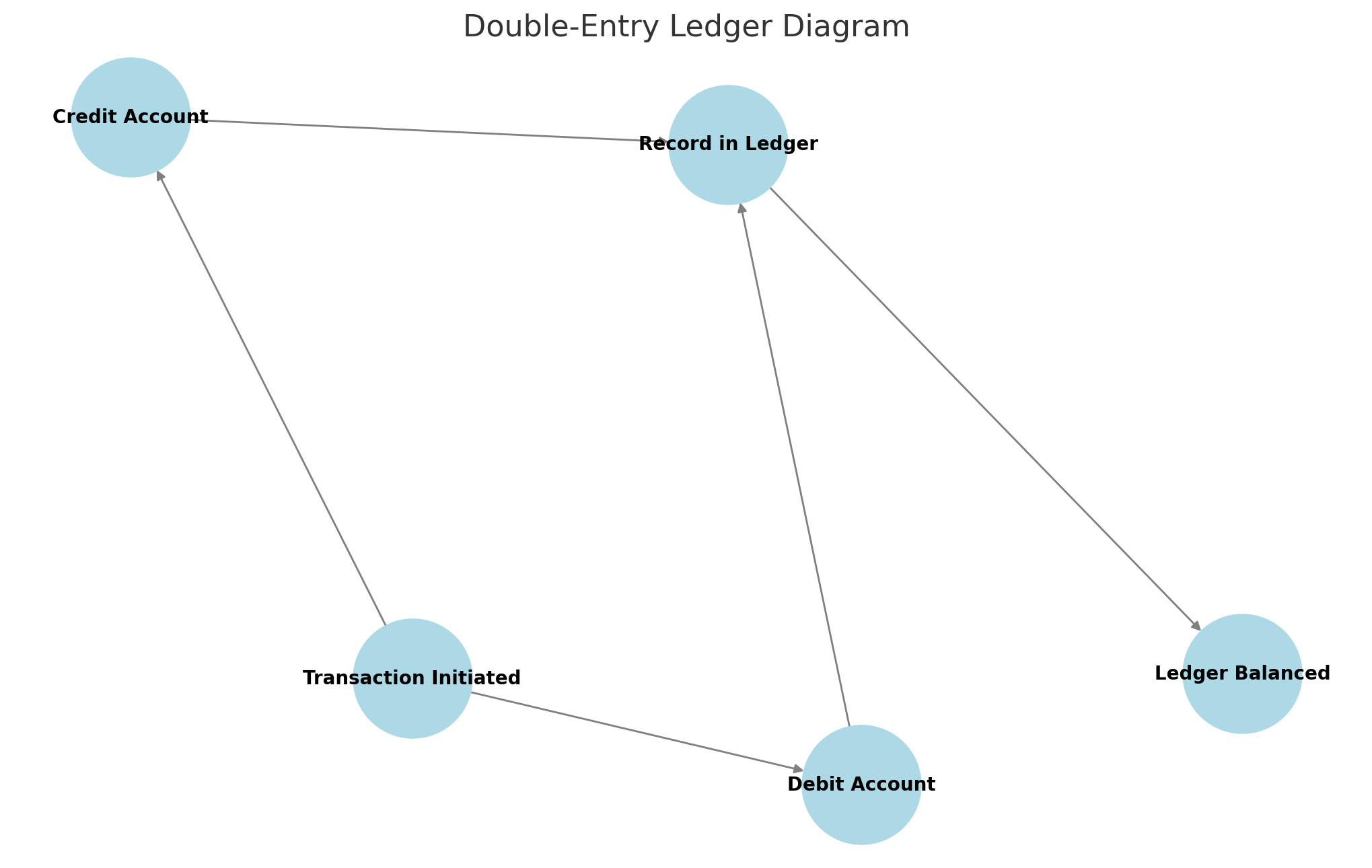
🔍 Diagram: The Double-Entry Ledger Diagram above illustrates how each financial transaction is recorded with a debit and a corresponding credit, ensuring that the ledger remains balanced and accurate.
By designing a well-structured database with appropriate constraints, relationships, and transactional integrity, we enforce ACID compliance within our banking ledger system. The next section will cover Transaction Management & Isolation Levels to further strengthen reliability and concurrency control.
Tip: Understanding isolation levels (READ COMMITTED, REPEATABLE READ, SERIALIZABLE) will help in designing a banking system that prevents race conditions and ensures data accuracy.
Section 3: Database Schema Design for ACID Compliance
In designing the database schema for the Banking Ledger System, ensuring ACID compliance is paramount. A well-structured schema will provide the foundation for atomic transactions, data consistency, isolation, and durability. Below, we define the core tables, relationships, constraints, and indexing strategies that support an ACID-compliant banking system.
3.1 Core Tables & Relationships
The banking ledger system consists of several key tables that represent users, accounts, transactions, and logs. Each table is structured to enforce data integrity and transaction reliability.
The following Entity-Relationship Diagram (ERD) visually represents the core tables and their relationships within the Banking Ledger System.
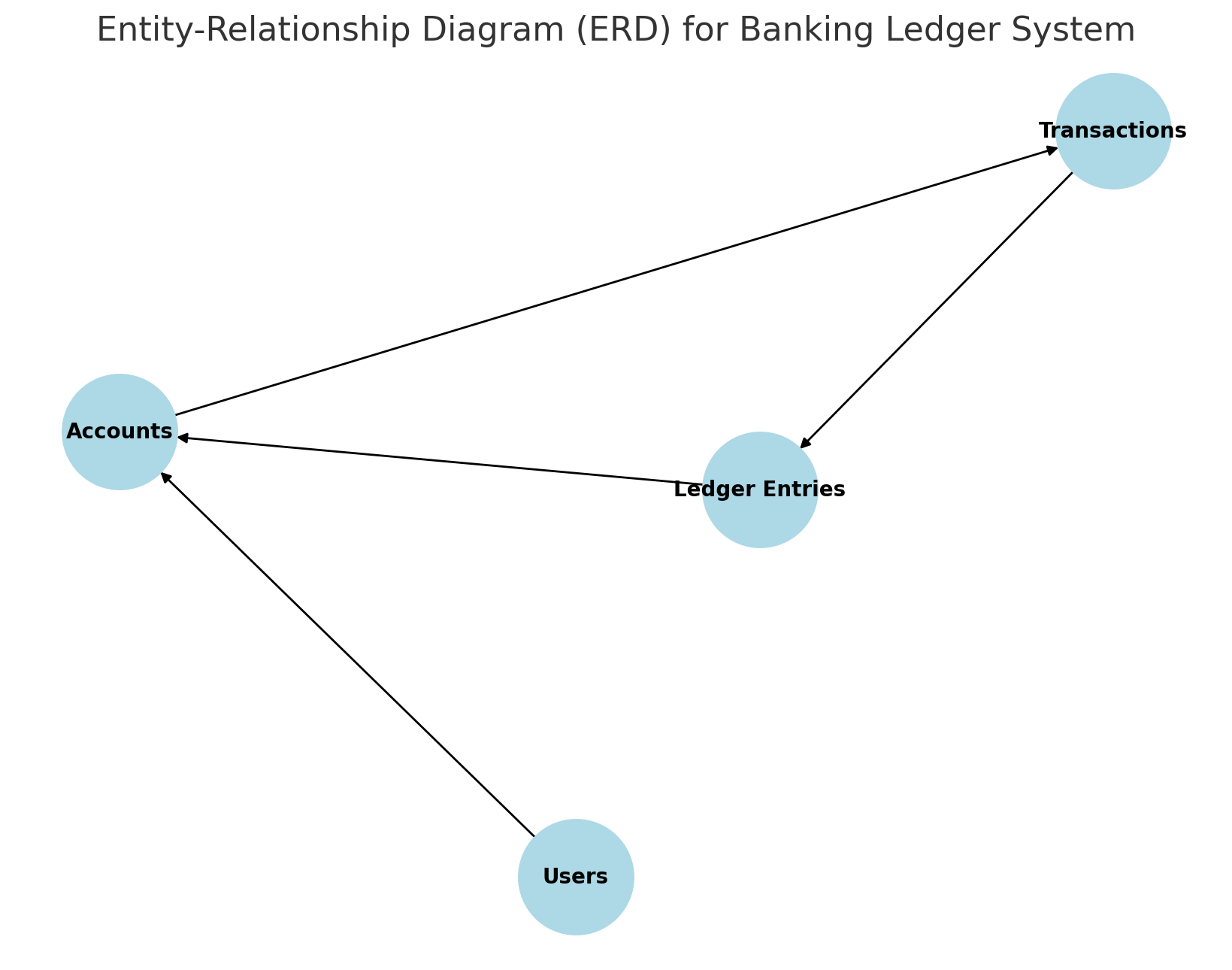
Accounts Table
This table stores details of each bank account.
1
2
3
4
5
6
7
8
9
CREATE TABLE accounts (
account_id SERIAL PRIMARY KEY,
user_id INT NOT NULL,
account_type VARCHAR(20) CHECK (account_type IN ('checking', 'savings', 'credit')),
balance DECIMAL(15,2) NOT NULL DEFAULT 0,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(user_id) ON DELETE CASCADE
);
Info: Each account must be linked to a valid user to maintain referential integrity. The
ON DELETE CASCADEensures that if a user is deleted, their accounts are also removed.
Users Table
Stores information about the account holders.
1
2
3
4
5
6
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
full_name VARCHAR(100) NOT NULL,
email VARCHAR(255) UNIQUE NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Info: The email field is marked as
UNIQUEto prevent duplicate user registrations.
Transactions Table
Maintains records of all financial transactions.
1
2
3
4
5
6
7
8
9
CREATE TABLE transactions (
transaction_id SERIAL PRIMARY KEY,
account_id INT NOT NULL,
transaction_type VARCHAR(10) CHECK (transaction_type IN ('deposit', 'withdrawal', 'transfer')),
amount DECIMAL(15,2) NOT NULL,
status VARCHAR(10) CHECK (status IN ('pending', 'completed', 'failed')) DEFAULT 'pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (account_id) REFERENCES accounts(account_id) ON DELETE CASCADE
);
Info: Each transaction must have a valid
account_id, and thestatusfield ensures clear tracking of the transaction state.
Ledger Entries Table
Tip: Double-entry accounting ensures that for every transaction, a corresponding debit and credit entry exist. This helps maintain a reliable audit trail.
A double-entry bookkeeping system to ensure accurate tracking.
1
2
3
4
5
6
7
8
9
10
11
CREATE TABLE ledger_entries (
ledger_id SERIAL PRIMARY KEY,
transaction_id INT NOT NULL,
debit_account INT NOT NULL,
credit_account INT NOT NULL,
amount DECIMAL(15,2) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (transaction_id) REFERENCES transactions(transaction_id) ON DELETE CASCADE,
FOREIGN KEY (debit_account) REFERENCES accounts(account_id),
FOREIGN KEY (credit_account) REFERENCES accounts(account_id)
);
:::info This Schema Diagram outlines the key tables, their columns, and constraints such as Primary Keys (PK), Foreign Keys (FK), Unique Constraints, and Checks to ensure data integrity. :::
1
2
3
4
5
6
| Table Name | Columns | Constraints |
| ------------------ | ------------------------------------------------------------------------------------------------------------ | ----------------------------------------------------------------------------------------------------- |
| **Users** | `user_id (PK)`, `full_name`, `email (UNIQUE)`, `created_at` | PK: `user_id`, UNIQUE: `email` |
| **Accounts** | `account_id (PK)`, `user_id (FK)`, `account_type`, `balance`, `created_at`, `updated_at` | PK: `account_id`, FK: `user_id (Users)`, CHECK: `account_type` |
| **Transactions** | `transaction_id (PK)`, `account_id (FK)`, `transaction_type`, `amount`, `status`, `created_at` | PK: `transaction_id`, FK: `account_id (Accounts)`, CHECK: `transaction_type & status` |
| **Ledger Entries** | `ledger_id (PK)`, `transaction_id (FK)`, `debit_account (FK)`, `credit_account (FK)`, `amount`, `created_at` | PK: `ledger_id`, FK: `transaction_id (Transactions)`, FK: `debit_account & credit_account (Accounts)` |
3.2 Normalization & Data Integrity
Tip: Using a normalized schema helps eliminate redundancy and maintain data integrity. Ensure that each table has only the necessary columns.
To maintain ACID compliance, normalization is applied:
1NF (First Normal Form): All columns contain atomic values, ensuring data is stored efficiently.
2NF (Second Normal Form): No partial dependencies; tables are broken down to avoid redundancy.
3NF (Third Normal Form): No transitive dependencies; ensuring each table has only the necessary columns.
Data integrity measures include:
FOREIGN KEY constraints to prevent orphaned records.
CHECK constraints to enforce valid values.
DEFAULT values to ensure proper data initialization.
3.3 Constraints & Indexing
Tip: Adding indexes to frequently queried columns improves database performance. However, excessive indexing can slow down
INSERTandUPDATEoperations.
To optimize performance and enforce integrity:
PRIMARY KEY constraints ensure unique identification of records.
FOREIGN KEY constraints enforce referential integrity.
INDEXES are added to speed up queries:
1 2
CREATE INDEX idx_transactions_account_id ON transactions(account_id); CREATE INDEX idx_ledger_transaction_id ON ledger_entries(transaction_id);
UNIQUE constraints prevent duplicate entries in user emails and transactions.
3.4 Transactional Considerations
Info: Ensuring proper transaction handling with
BEGIN TRANSACTION,COMMIT, andROLLBACKstatements is crucial for atomicity.
ACID compliance is reinforced by:
Atomicity: Transactions are wrapped in a
BEGIN TRANSACTIONandCOMMITto ensure either full execution or rollback.Consistency: Constraints and triggers maintain data validity.
Isolation: Proper transaction isolation levels (e.g.,
SERIALIZABLE) prevent race conditions.Durability: Transaction logs (Write-Ahead Logging) ensure recovery in case of failure.
Tip: Use database triggers to automatically enforce rules, such as preventing overdrafts or logging suspicious transactions.
This Transaction Flow Diagram illustrates how a transaction moves through the system from initiation to completion, ensuring data integrity and financial accuracy.
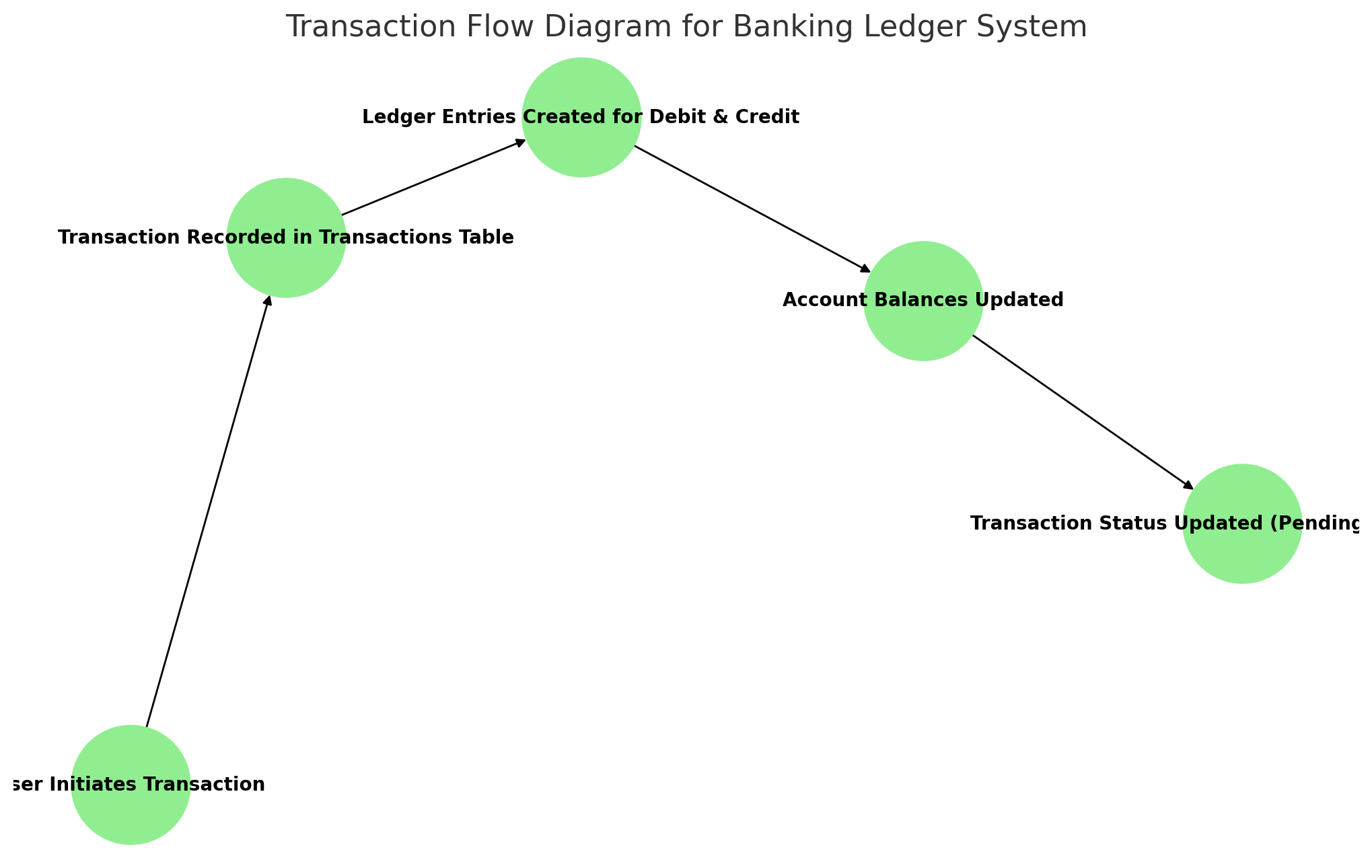
Example of an Atomic Transaction:
1
2
3
4
5
6
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE account_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE account_id = 2;
INSERT INTO transactions (account_id, transaction_type, amount, status)
VALUES (1, 'transfer', 100, 'completed');
COMMIT;
This ensures either all operations succeed together, or none take effect, maintaining ledger integrity.
The following ACID Compliance Process Flow Diagram demonstrates how the Banking Ledger System enforces Atomicity, Consistency, Isolation, and Durability through structured transaction management.
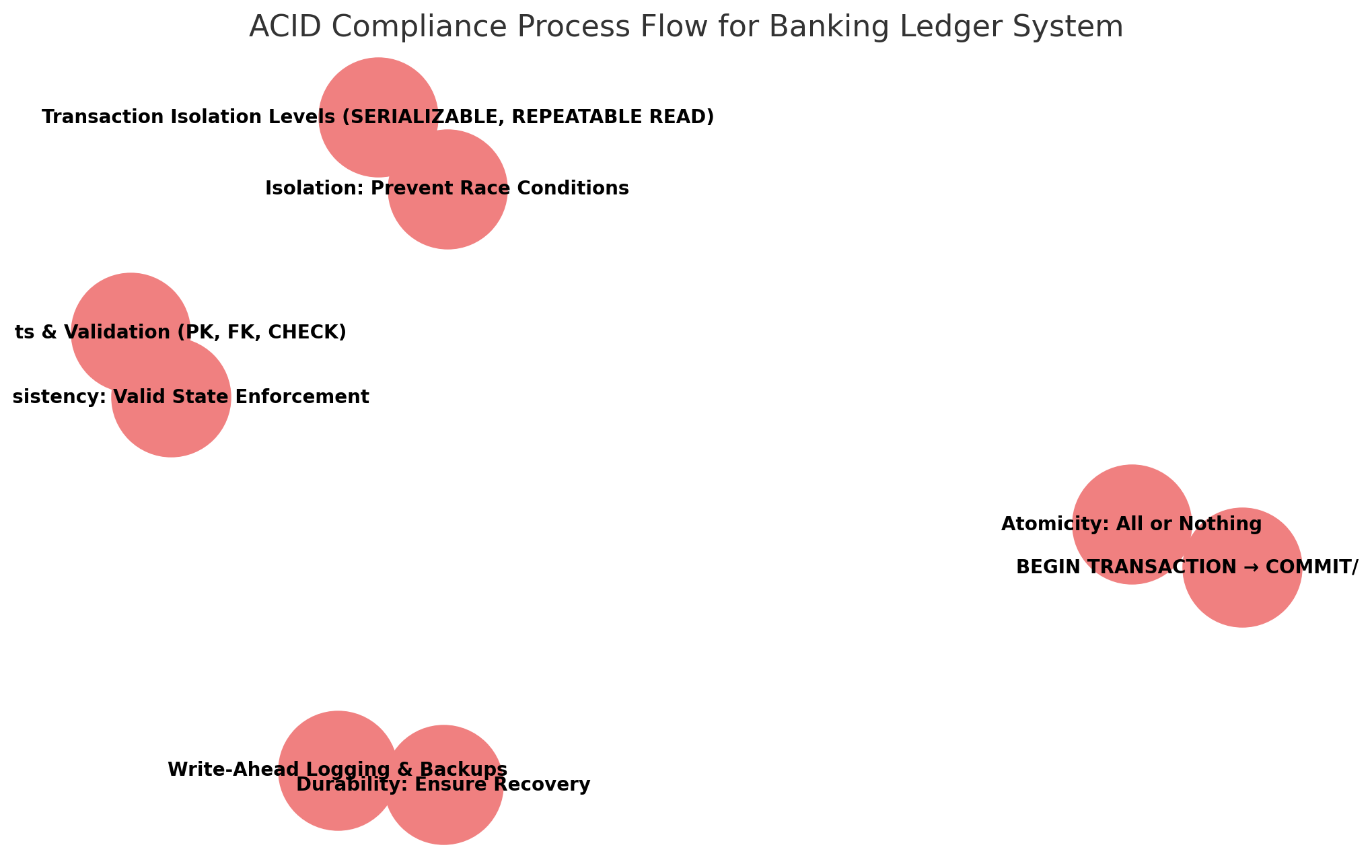
With this robust schema, the banking ledger system maintains data integrity, transaction reliability, and optimal performance while adhering to ACID principles. The next section will delve into Isolation Levels and Concurrency Control to ensure safe and efficient multi-user transactions.
Section 4: Concurrency Control & Isolation Levels
4.1 Introduction
Ensuring data consistency in a multi-user banking ledger system requires robust concurrency control mechanisms. Without proper isolation levels, concurrent transactions could lead to issues like lost updates, dirty reads, and phantom reads. This section explores isolation levels, locking mechanisms, and strategies to prevent data anomalies in a high-volume transactional system.
Info: Concurrency control is essential in banking systems to prevent data corruption and ensure transactions are processed accurately, even when multiple users access the system simultaneously.
4.2 Common Concurrency Issues in Banking Systems
1. Dirty Reads
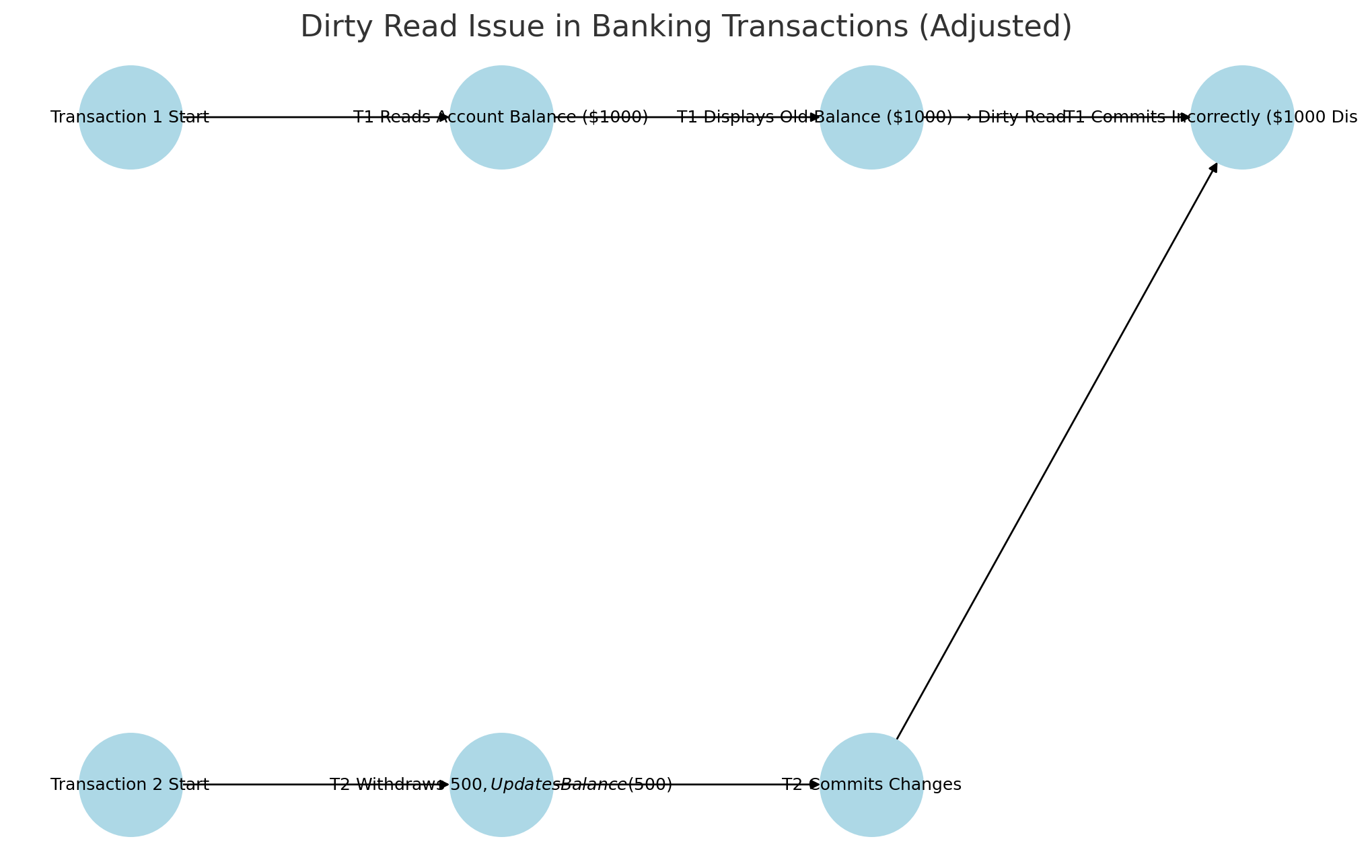
Occurs when a transaction reads uncommitted data from another transaction, leading to inconsistencies.
Example: If a user checks their account balance while a withdrawal is still in progress, they might see an incorrect balance.
Tip: To prevent dirty reads, use the Read Committed isolation level or higher. This ensures transactions only read committed changes.
2. Lost Updates
Happens when two transactions read and modify the same data concurrently, but one update is lost due to overwrites.
Example: Two users simultaneously transferring money from the same account, causing an incorrect final balance.
Info: Lost updates can be avoided using pessimistic locking or optimistic concurrency control depending on the workload and performance requirements.
3. Non-Repeatable Reads
Occurs when a transaction reads the same data twice but gets different results because another transaction modified the data in between.
Tip: The Repeatable Read isolation level prevents non-repeatable reads by ensuring that if a row is read twice within a transaction, it remains unchanged.
4. Phantom Reads
Happens when a transaction reads a set of rows but gets different results on re-execution because another transaction inserted new records.
Info: To eliminate phantom reads, use Serializable isolation, which enforces strict row-level locking or multi-version concurrency control (MVCC).
4.3 Database Isolation Levels
1
2
3
4
5
6
7
| Isolation Level | Dirty Reads Prevented | Non-Repeatable Reads Prevented | Phantom Reads Prevented | Performance Impact |
| ---------------- | --------------------- | ------------------------------ | ----------------------- | ------------------ |
| Read Uncommitted | ❌ No | ❌ No | ❌ No | Low |
| Read Committed | ✅ Yes | ❌ No | ❌ No | Medium |
| Repeatable Read | ✅ Yes | ✅ Yes | ❌ No | High |
| Serializable | ✅ Yes | ✅ Yes | ✅ Yes | Very High |
To prevent concurrency issues, databases offer different isolation levels that control how transactions interact with each other.
Tip: Choosing the right isolation level is a balance between data consistency and performance. Higher isolation levels reduce anomalies but may slow down system performance.
1. Read Uncommitted (Lowest Isolation)
Transactions can read uncommitted changes from other transactions.
Risk: Allows dirty reads, lost updates.
Use Case: Not recommended for financial systems.
2. Read Committed
Transactions can only read committed changes.
Risk: Prevents dirty reads but allows non-repeatable reads.
Use Case: Suitable for banking systems where accuracy is needed but strict locking is unnecessary.
3. Repeatable Read
Prevents dirty reads and non-repeatable reads by ensuring data consistency within a transaction.
Risk: Still allows phantom reads.
Use Case: Useful for preventing inconsistent account balances.
4. Serializable (Highest Isolation)
Transactions are executed sequentially to prevent all concurrency issues.
Risk: Slower performance due to high locking.
Use Case: Required for critical financial transactions where absolute accuracy is a must.
4.4 Deadlock Scenarios and Locking Mechanisms
Deadlocks occur when two or more transactions block each other by waiting for resources locked by another transaction.
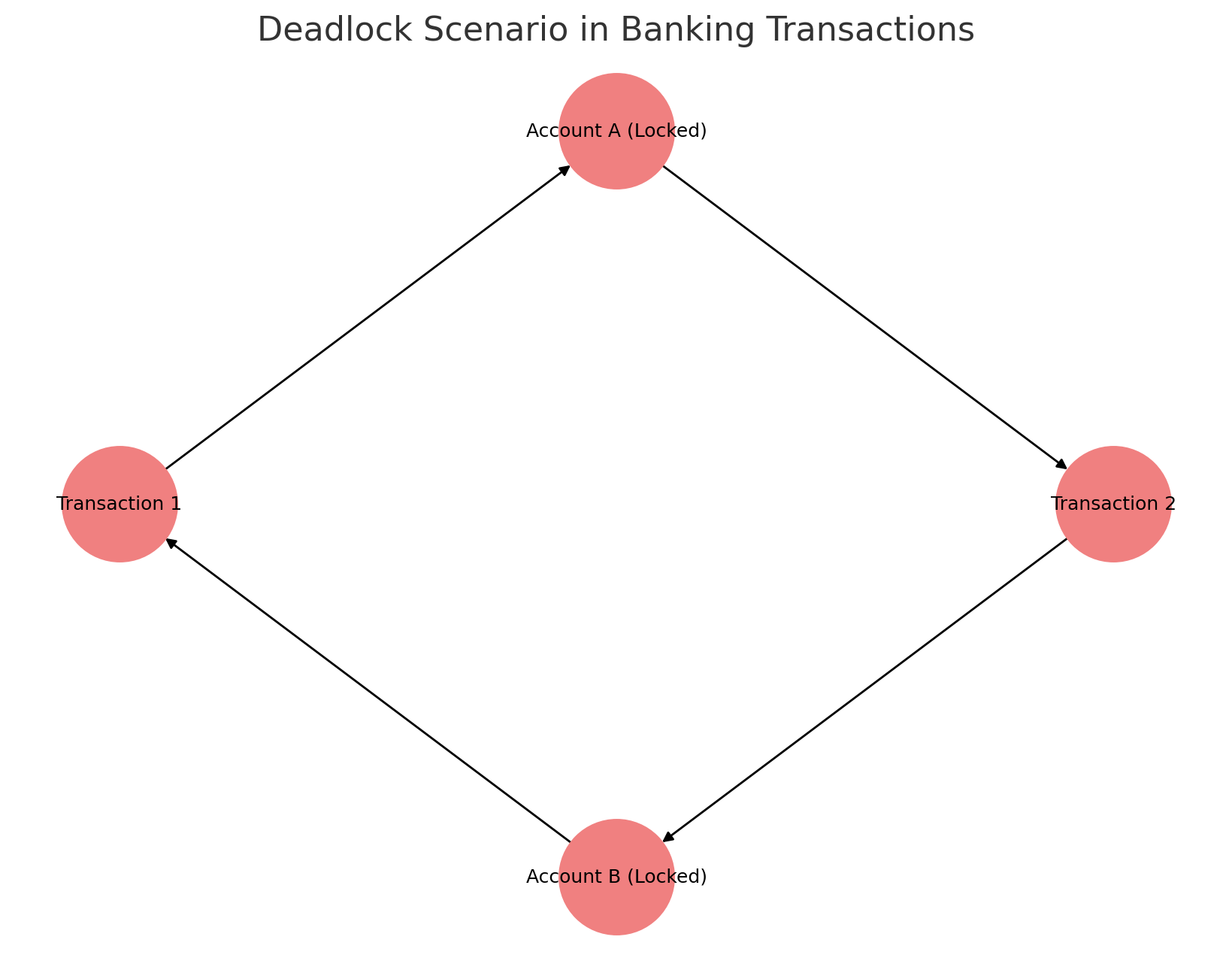
Info: Deadlocks occur when transactions hold locks on different resources and wait indefinitely. Implementing deadlock detection and resolution can prevent system slowdowns.
Using Locks to Prevent Anomalies
Explicit Locking: Prevents other transactions from modifying data.
1
SELECT * FROM Accounts WHERE account_id = 1 FOR UPDATE;
Tip: Use row-level locks instead of table locks to improve concurrency while avoiding unnecessary transaction blocking.
Deadlock Handling: Detect and resolve conflicts between concurrent transactions.
1
SET DEADLOCK_PRIORITY HIGH;
Info: Some databases implement deadlock detection algorithms to automatically abort and retry transactions when deadlocks are detected.
4.5 Optimistic vs. Pessimistic Concurrency Control
Optimistic concurrency control (OCC) assumes that conflicts are rare and checks for conflicts at commit time, whereas pessimistic concurrency control locks data upfront to prevent conflicts.
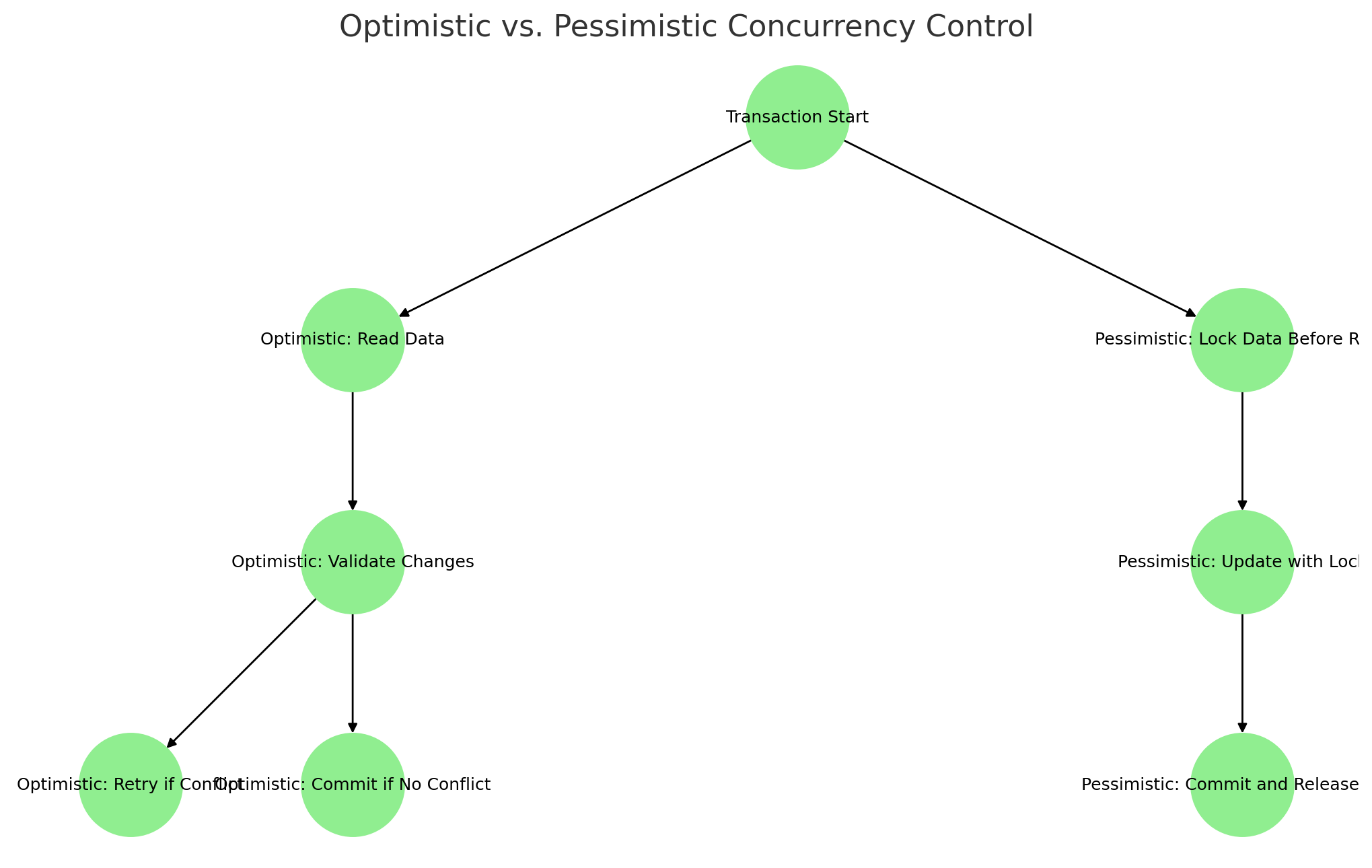
Tip: Optimistic concurrency control (OCC) is ideal for high-read, low-write workloads, while pessimistic locking is better for environments with frequent data modifications.
4.6 Best Practices for Concurrency Control
Choose the right isolation level based on system requirements.
Use row-level locking instead of table-level locking to improve performance.
Implement optimistic concurrency control (OCC) where transactions check if the data has changed before committing.
Monitor and resolve deadlocks by analyzing transaction logs and using timeout settings.
Partition data logically to reduce contention on frequently accessed tables.
Info: Database partitioning can significantly improve transaction throughput by distributing data across multiple storage segments, reducing contention.
4.7 Summary
Concurrency control is essential for maintaining accuracy in a multi-user banking ledger system. By selecting appropriate isolation levels, implementing locking mechanisms, and following best practices, we can prevent data anomalies while ensuring system performance. The next section will focus on Transaction Handling & Recovery Strategies, detailing rollback mechanisms, savepoints, and crash recovery techniques.
Section 5: Ensuring ACID Compliance in Banking Transactions
In this section, we will explore the strategies and techniques used to ensure ACID (Atomicity, Consistency, Isolation, Durability) compliance in banking transactions. A robust banking ledger system must adhere to these properties to maintain data integrity and reliability.

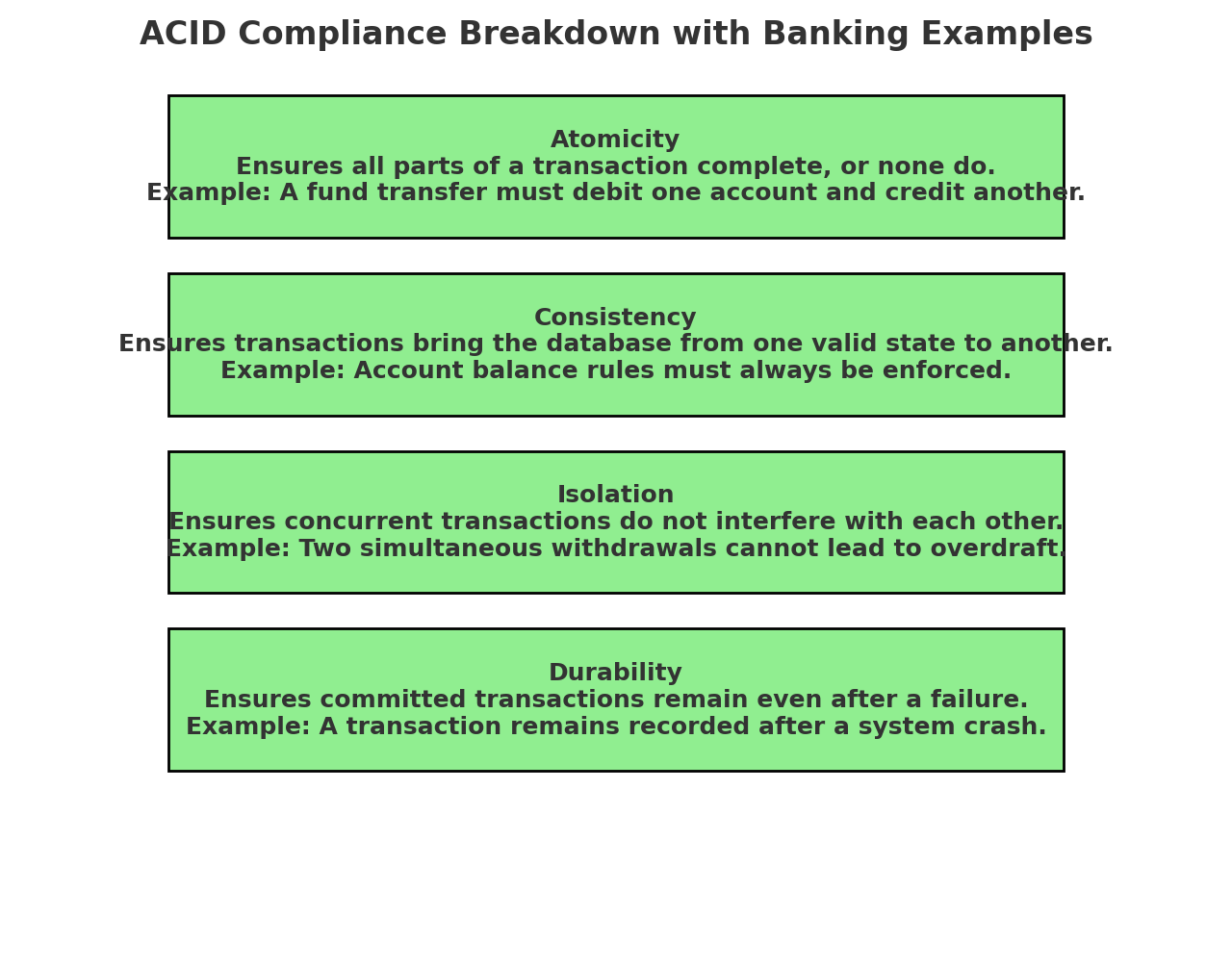
This diagram summarizes the four key ACID properties—Atomicity, Consistency, Isolation, and Durability—essential for ensuring reliable banking transactions.
5.1 Atomicity: All-or-Nothing Transactions
Atomicity guarantees that a transaction is either fully completed or fully rolled back in case of failure. This is crucial in banking, where partial transactions can lead to data corruption or financial inconsistencies.
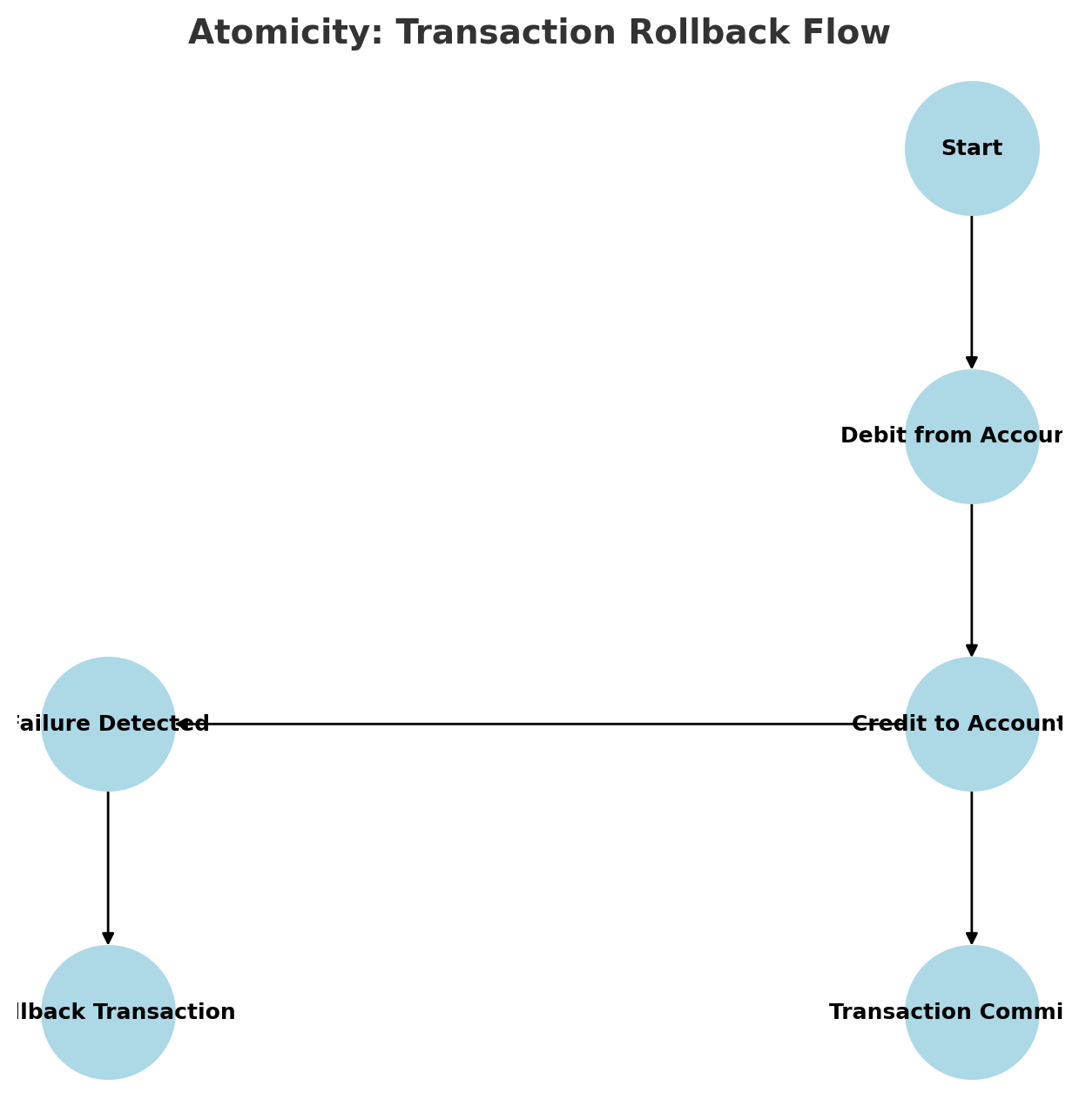
This diagram illustrates how transactions are either fully completed or rolled back in case of failure, ensuring Atomicity.
Info: Consider a scenario where a user transfers $500 from their checking account to their savings account. If the debit from checking succeeds but the credit to savings fails, atomicity ensures that the entire transaction is rolled back, preventing an imbalance.
Implementation Strategies:
Use database transactions (
BEGINTRANSACTION,COMMIT,ROLLBACK).Implement exception handling mechanisms to detect failures and trigger rollbacks.
5.2 Consistency: Enforcing Data Validity
Consistency ensures that the database remains in a valid state before and after a transaction. Constraints, rules, and validation mechanisms help enforce this principle.
Tip: Define foreign key constraints and validation rules at the database level to prevent invalid entries. This helps maintain referential integrity and prevents orphaned records.
Consistency: Data Validation Check
1
2
3
4
5
6
7
| Column Name | Data Type | Constraints |
| ----------- | ------------- | ----------------------------------------- |
| account_id | INT (PK) | PRIMARY KEY |
| customer_id | INT (FK) | FOREIGN KEY → Customers(customer_id) |
| balance | DECIMAL(10,2) | CHECK (balance >= 0) |
| currency | VARCHAR(3) | CHECK (currency IN ('USD', 'EUR', 'GBP')) |
| status | VARCHAR(10) | CHECK (status IN ('Active', 'Closed')) |
This table highlights database constraints such as
PRIMARY KEY,FOREIGN KEY, andCHECKrules to enforce data consistency in a banking ledger.
Implementation Strategies:
Use constraints such as
CHECK,FOREIGN KEY, andUNIQUE.Validate input data before committing transactions.
Implement stored procedures to encapsulate business logic.
5.3 Isolation: Preventing Data Anomalies
Isolation ensures that concurrent transactions do not interfere with each other, maintaining data accuracy. Different isolation levels provide varying degrees of concurrency control.
Info: Isolation Levels:
Read Uncommitted – Allows dirty reads (least restrictive).
Read Committed – Prevents dirty reads but allows non-repeatable reads.
Repeatable Read – Prevents dirty and non-repeatable reads.
Serializable – Strictest level, ensuring full isolation.
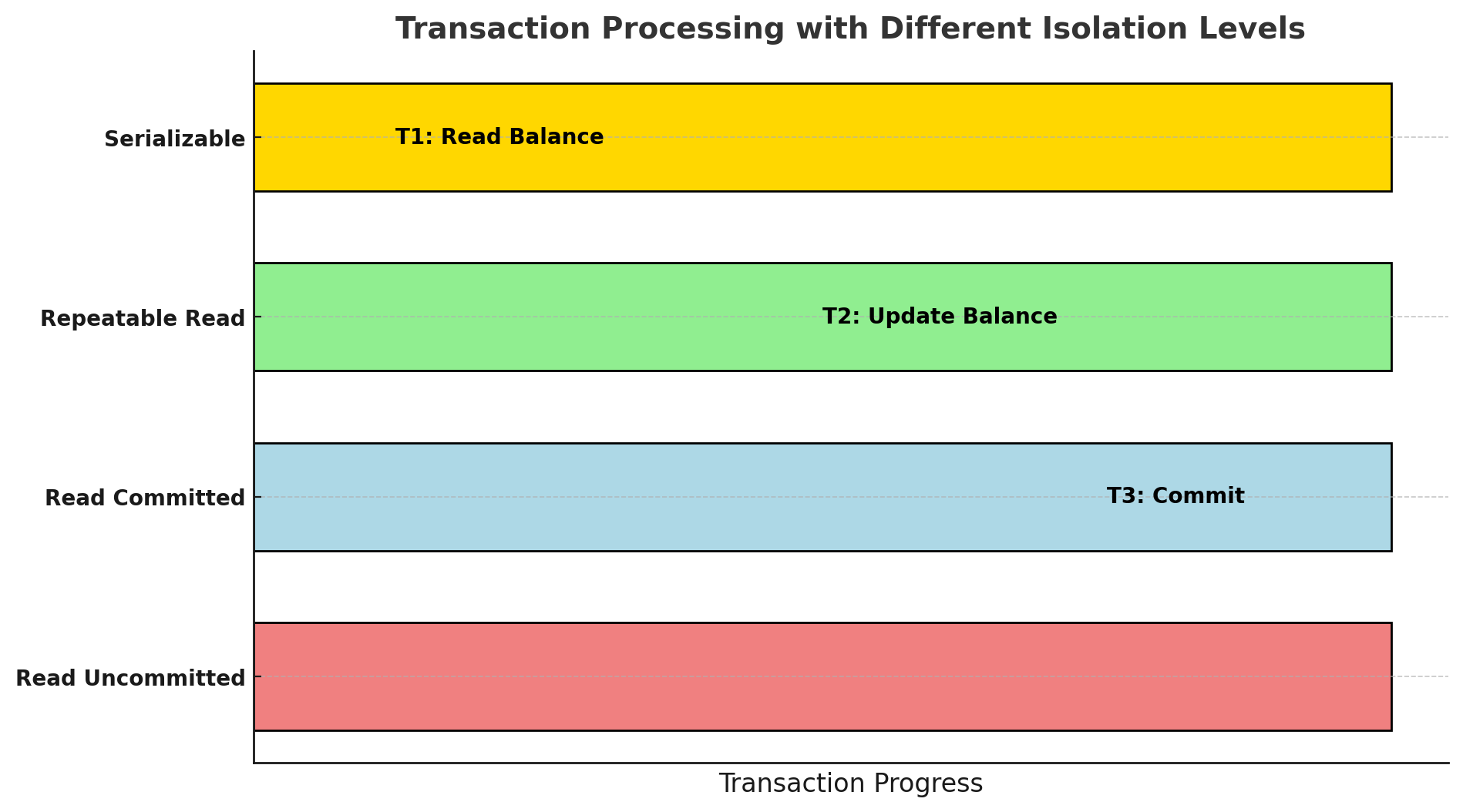
This timeline illustrates how transactions behave under different isolation levels, from Read Uncommitted to Serializable.
Implementation Strategies:
Use appropriate isolation levels (
SET TRANSACTION ISOLATION LEVELin SQL).Implement row-level locking to prevent race conditions.
Utilize optimistic or pessimistic concurrency control as needed.
5.4 Durability: Ensuring Data Persistence
Durability guarantees that once a transaction is committed, it remains permanently stored, even in case of system failure.
Tip: Implement database replication and periodic backups to enhance durability and prevent data loss.
Implementation Strategies:
Enable write-ahead logging (WAL) to persist changes before applying them.
Use RAID storage solutions for fault tolerance.
Implement database replication and backup policies.
5.5 Practical Implementation in SQL
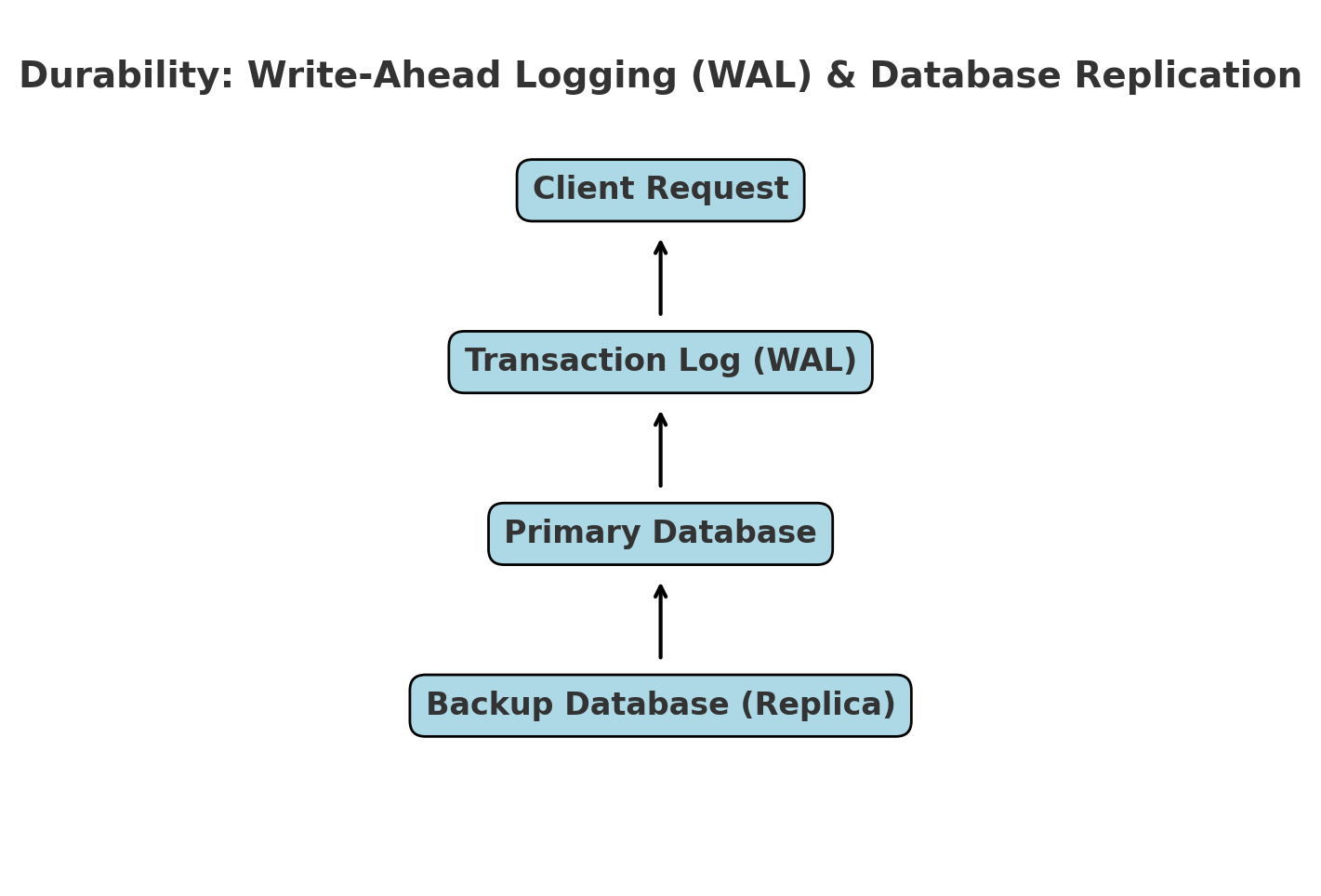
This block diagram demonstrates how transactions are permanently stored using Write-Ahead Logging (WAL) and database replication to ensure durability.
Here’s a SQL example demonstrating ACID compliance in a fund transfer operation:
1
2
3
4
5
6
7
8
9
BEGIN TRANSACTION;
UPDATE accounts SET balance = balance - 500 WHERE account_id = 1;
UPDATE accounts SET balance = balance + 500 WHERE account_id = 2;
IF @@ERROR <> 0
ROLLBACK TRANSACTION;
ELSE
COMMIT TRANSACTION;
Info: This transaction ensures atomicity (all steps succeed or none), consistency (balances remain accurate), isolation (executed independently), and durability (committed changes persist).
By implementing these strategies, we ensure that banking ledger systems maintain high integrity, security, and resilience, making them reliable for financial operations.
Section 6: Transaction Processing and Concurrency Control
Overview
Transaction processing in a banking ledger system must adhere to the ACID (Atomicity, Consistency, Isolation, Durability) properties to ensure reliable and secure financial operations. This section explores the mechanisms used to process transactions efficiently while maintaining data integrity and handling concurrent access.
6.1 Transaction Lifecycle in Banking Systems
A transaction in the banking ledger system follows a structured lifecycle:
- Transaction Initiation: A user initiates a banking operation (e.g., deposit, withdrawal, transfer).
- Validation & Authorization: The system verifies the account status, balance sufficiency, and compliance with business rules.
- Execution & Logging: The SQL transaction executes and logs changes in the transaction history table.
- Commit or Rollback: Based on success or failure, the system either commits the transaction (persisting changes) or rolls it back (restoring the previous state).
- Notification & Auditing: The system records the final state in audit logs and notifies the user.
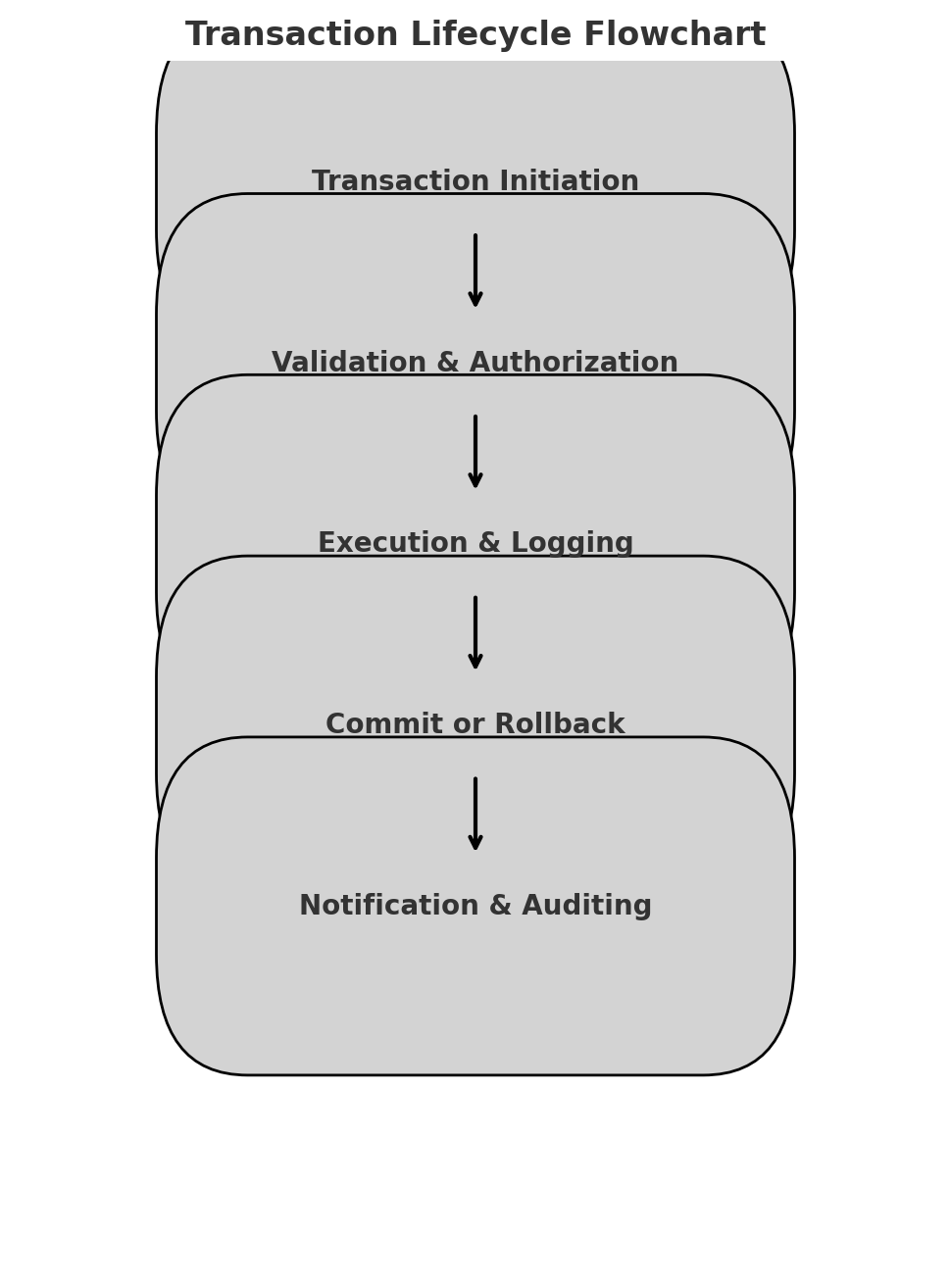
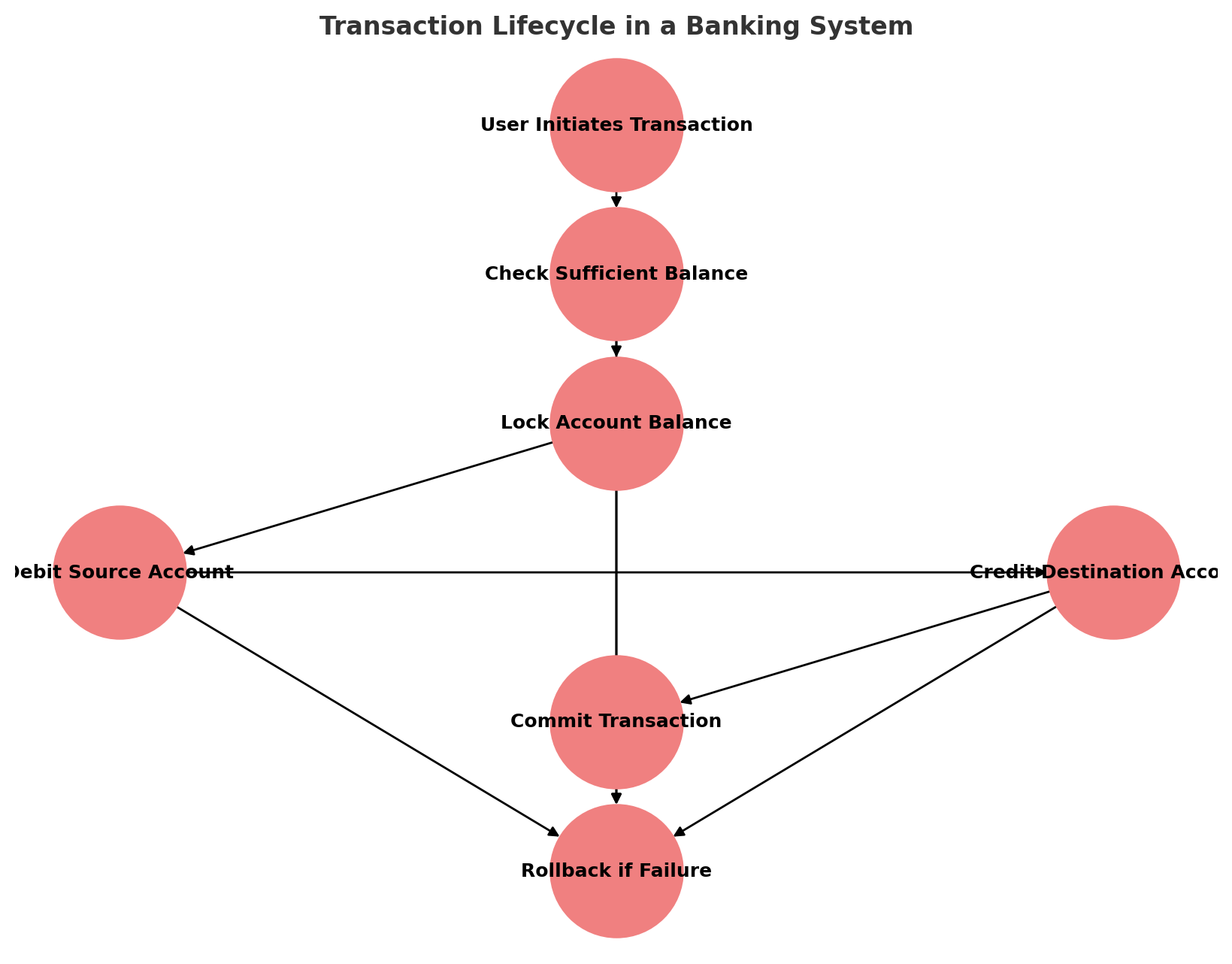
Info: Understanding Transaction Flow This diagram shows the sequence of steps in a banking transaction, ensuring that each phase (initiation, validation, execution, and commit/rollback) follows a structured process to maintain data integrity.
6.2 Ensuring ACID Compliance
To maintain data integrity in a financial system, transactions must fulfill the ACID principles:
- Atomicity: Ensures that all steps in a transaction are completed successfully, or none at all.
- Solution: Use
SQL BEGIN TRANSACTION,COMMIT, andROLLBACKto ensure atomic execution.
- Solution: Use
- Consistency: Guarantees that the database remains in a valid state before and after the transaction.
- Solution: Enforce constraints like
CHECK,FOREIGN KEY, and triggers to prevent invalid transactions.
- Solution: Enforce constraints like
- Isolation: Prevents concurrent transactions from interfering with each other.
- Solution: Implement Isolation Levels such as
READ COMMITTEDorSERIALIZABLEto prevent dirty reads, non-repeatable reads, and phantom reads.
- Solution: Implement Isolation Levels such as
- Durability: Ensures that committed transactions are permanently recorded, even in case of system failures.
- Solution: Use database Write-Ahead Logging (WAL) or Redo Logs to ensure durability.
Info: Why Isolation Matters in Banking In financial systems, isolation ensures that concurrent transactions do not interfere with each other. For example, if two customers attempt to withdraw money simultaneously from the same account, isolation prevents them from exceeding the available balance due to race conditions. Without proper isolation, a bank could allow multiple withdrawals before updating the balance, leading to financial discrepancies.
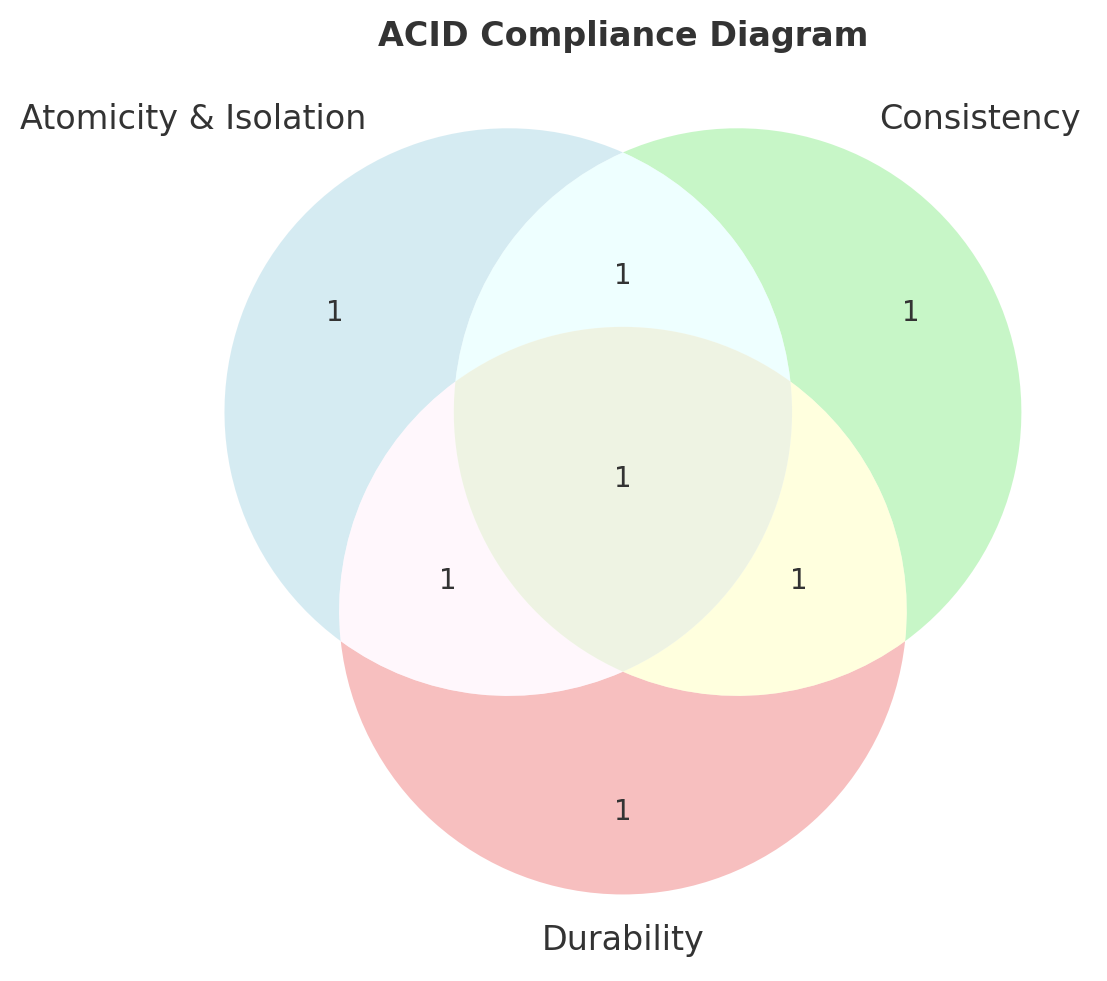
Info: How ACID Protects Banking Transactions ACID properties ensure that all financial transactions remain valid and consistent. Atomicity guarantees all-or-nothing execution, Isolation prevents interference, Consistency maintains business rules, and Durability ensures committed data persists.
6.3 Concurrency Control Mechanisms
Banking systems require high concurrency while preventing anomalies like race conditions, double withdrawals, and lost updates. The following techniques help achieve this:
- Pessimistic Locking
- Uses explicit locks (
SELECT … FOR UPDATE) to prevent conflicts in concurrent transactions. - Best suited for high-value transactions where consistency is critical.
- Uses explicit locks (
- Optimistic Locking
- Relies on versioning (
ROW VERSIONorTIMESTAMP) to detect conflicting updates. - Best suited for high-performance banking queries where conflicts are rare.
- Relies on versioning (
- Isolation Levels in SQL
tip: Choosing the Right Isolation Level Use
READ COMMITTEDfor general banking queries to balance performance and consistency. For critical transactions such as fund transfers,SERIALIZABLEis the safest choice, ensuring full isolation at the cost of reduced concurrency.

Tip: Choosing the Right Isolation Level The stricter the isolation level, the stronger the data integrity but at the cost of performance. This pyramid diagram illustrates the trade-offs, with
Serializableoffering the highest consistency andRead Uncommittedproviding the fastest execution.
| Isolation Level | Prevents Dirty Reads | Prevents Non-Repeatable Reads | Prevents Phantom Reads | Performance Impact |
|---|---|---|---|---|
| READ UNCOMMITTED | No | No | No | Fastest |
| READ COMMITTED | Yes | No | No | Moderate |
| REPEATABLE READ | Yes | Yes | No | Slower |
| SERIALIZABLE | Yes | Yes | Yes | Slowest (Full Locking) |
- Recommended for Banking: Use REPEATABLE READ for balance-related queries and SERIALIZABLE for transactions involving multiple accounts.
6.4 Example: Secure Funds Transfer Transaction
Here’s a SQL implementation of a secure funds transfer using ACID-compliant transactions:
Info: Atomicity in Banking Transactions In a funds transfer operation, both the sender’s deduction and the receiver’s deposit must occur together. If one step fails (e.g., insufficient funds), the entire transaction should be rolled back to prevent inconsistencies. This is why atomicity is essential in banking systems.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
BEGIN TRANSACTION;
-- Step 1: Deduct funds from Sender's account
UPDATE accounts
SET balance = balance - 500
WHERE account_id = 1001
AND balance >= 500;
-- Step 2: Add funds to Receiver's account
UPDATE accounts
SET balance = balance + 500
WHERE account_id = 2002;
-- Step 3: Record transaction log
INSERT INTO transaction_history (sender_id, receiver_id, amount, transaction_date)
VALUES (1001, 2002, 500, NOW());
-- Step 4: Check if both updates were successful
IF @@ROWCOUNT = 0
ROLLBACK; -- Undo transaction if an error occurs
ELSE
COMMIT; -- Finalize transaction
Key Protections:
- Ensures atomicity (both updates succeed, or neither does).
- Prevents negative balances with
balance >= 500check. - Maintains durability with transaction logs.
6.5 Deadlock Handling
Deadlocks occur when two transactions wait for each other indefinitely. Preventative strategies include:
- Lock Ordering: Always acquire locks in a predefined order.
- Timeout-Based Deadlock Detection: Use
SET LOCK_TIMEOUT 5000; to auto-abort stalled transactions. - Partitioning Hot Data: Avoids excessive locking on high-traffic accounts.
Tip: Preventing Deadlocks in High-Traffic Accounts To avoid deadlocks, ensure that all transactions acquire locks in the same order. Additionally, avoid long-running transactions that hold locks for extended periods. Optimizing queries and using index-based lookups can help reduce contention.
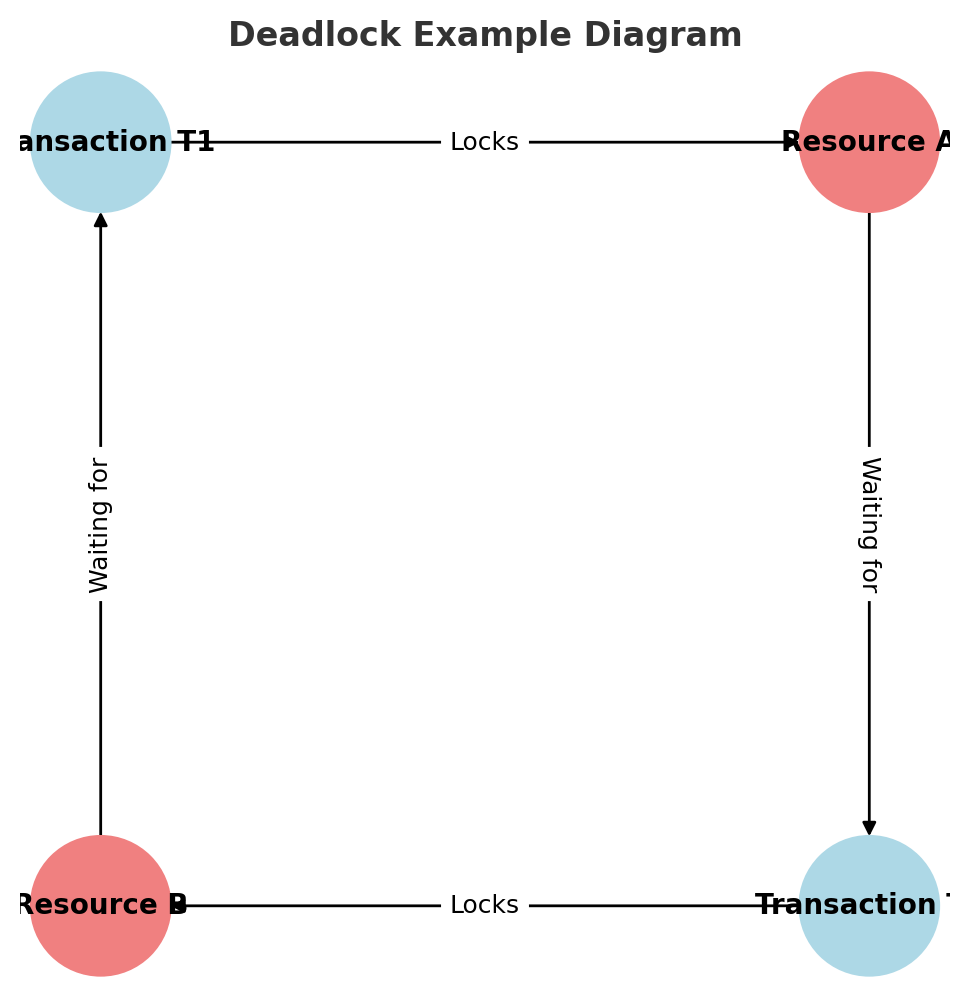
Info: Understanding Deadlocks Deadlocks occur when two transactions wait indefinitely for each other to release a resource. This diagram illustrates a classic deadlock scenario where
Transaction T1andTransaction T2hold and wait for the same resources, leading to a circular wait.
Conclusion
This section has outlined how transaction processing and concurrency control ensure data integrity and system reliability in banking operations. The next section will cover Database Performance Optimization & Indexing Strategies to improve query execution in high-transaction environments.
Section 7: Optimizing Performance, Security, and Scalability
A robust banking ledger system must be fast, secure, and scalable to handle high transaction volumes while maintaining financial accuracy. This section covers key techniques for:
- Optimizing performance with indexing, query tuning, and caching
- Ensuring security with encryption, authentication, and access control
- Scaling the system using replication, partitioning, and load balancing
7.1 Database Performance Optimization
Indexing Strategies for Faster Queries
Indexing speeds up searches and ensures smooth transaction processing. In a banking system, consider:
- Primary Indexes: Ensure fast lookups of accounts, transactions, and balances
- Composite Indexes: Improve queries involving multiple columns (e.g.,
account_id,transaction_date) - Partial Indexes: Optimize queries for high-traffic records (e.g., active accounts only)
Tip: Use composite indexes on frequently queried columns to speed up lookups and reduce full table scans.
Example: Adding an Index to Speed Up Account Balance Queries
1
CREATE INDEX idx_account_balance ON accounts(account_id, balance);
This allows quick retrieval of account balances without scanning the entire table.
Optimizing SQL Queries
- Avoid
SELECT *– Fetch only necessary columns to reduce overhead. - Use prepared statements to prevent SQL injection and optimize execution plans.
- Implement batch processing instead of multiple single inserts to reduce I/O:
1
2
INSERT INTO transactions (account_id, transaction_type, amount)
VALUES (101, 'deposit', 500), (102, 'withdrawal', 300), (103, 'transfer', 200);
Implementing Caching for High Performance
- Use Redis or Memcached to cache frequently accessed data (e.g., account balances).
- Store computed transaction summaries instead of recalculating them on every query.
- Set expiration policies to refresh cache periodically and prevent stale data.
Info: Caching frequently accessed data in Redis or Memcached can reduce database load and improve response times for high-traffic queries.
Example: Caching Account Balances in Redis
1
SET account:101:balance 500 EX 3600 # Cache balance for 1 hour
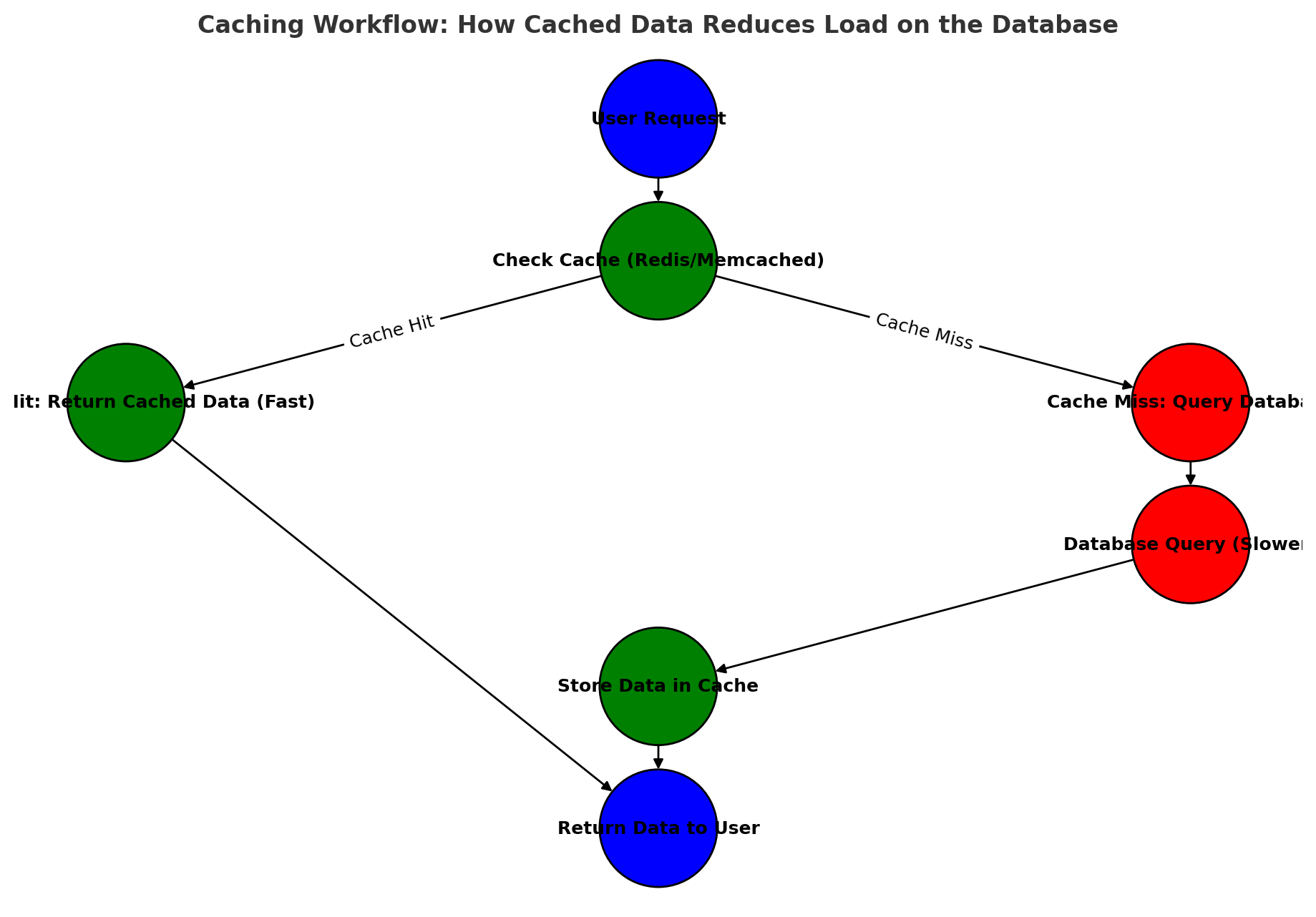
7.2 Security Best Practices for a Banking Ledger System
Data Encryption (At-Rest & In-Transit)
- Use AES-256 encryption for stored sensitive data (e.g., account numbers, transaction logs).
- Enable TLS (Transport Layer Security) for all communications between clients and the database.
Info: Encrypting sensitive fields such as account numbers and SSNs ensures that even if a database is compromised, the data remains unreadable.
Example: Encrypting Sensitive Data at Rest
1
2
ALTER TABLE accounts ADD COLUMN encrypted_ssn BYTEA;
UPDATE accounts SET encrypted_ssn = PGP_SYM_ENCRYPT('123-45-6789', 'encryption_key');
Role-Based Access Control (RBAC) & Least Privilege
- Use RBAC to restrict user permissions (e.g., tellers, auditors, system admins).
- Follow the Principle of Least Privilege (PoLP) – users should only have access to what they need.
Tip: Implement the Principle of Least Privilege (PoLP) to restrict users from accessing more data than necessary, reducing security risks.
Example: Creating a Read-Only Role for Auditors
1
2
CREATE ROLE auditor;
GRANT SELECT ON transactions TO auditor;
Secure API Gateway & Authentication
- Implement OAuth 2.0 and JWT for secure API authentication.
- Use an API Gateway (e.g., Azure API Management) to enforce security policies and rate limits.
- Enable Multi-Factor Authentication (MFA) for sensitive operations.
Example: Verifying API Requests with JWT
1
Authorization: Bearer eyJhbGciOiJIUzI1NiIsIn...
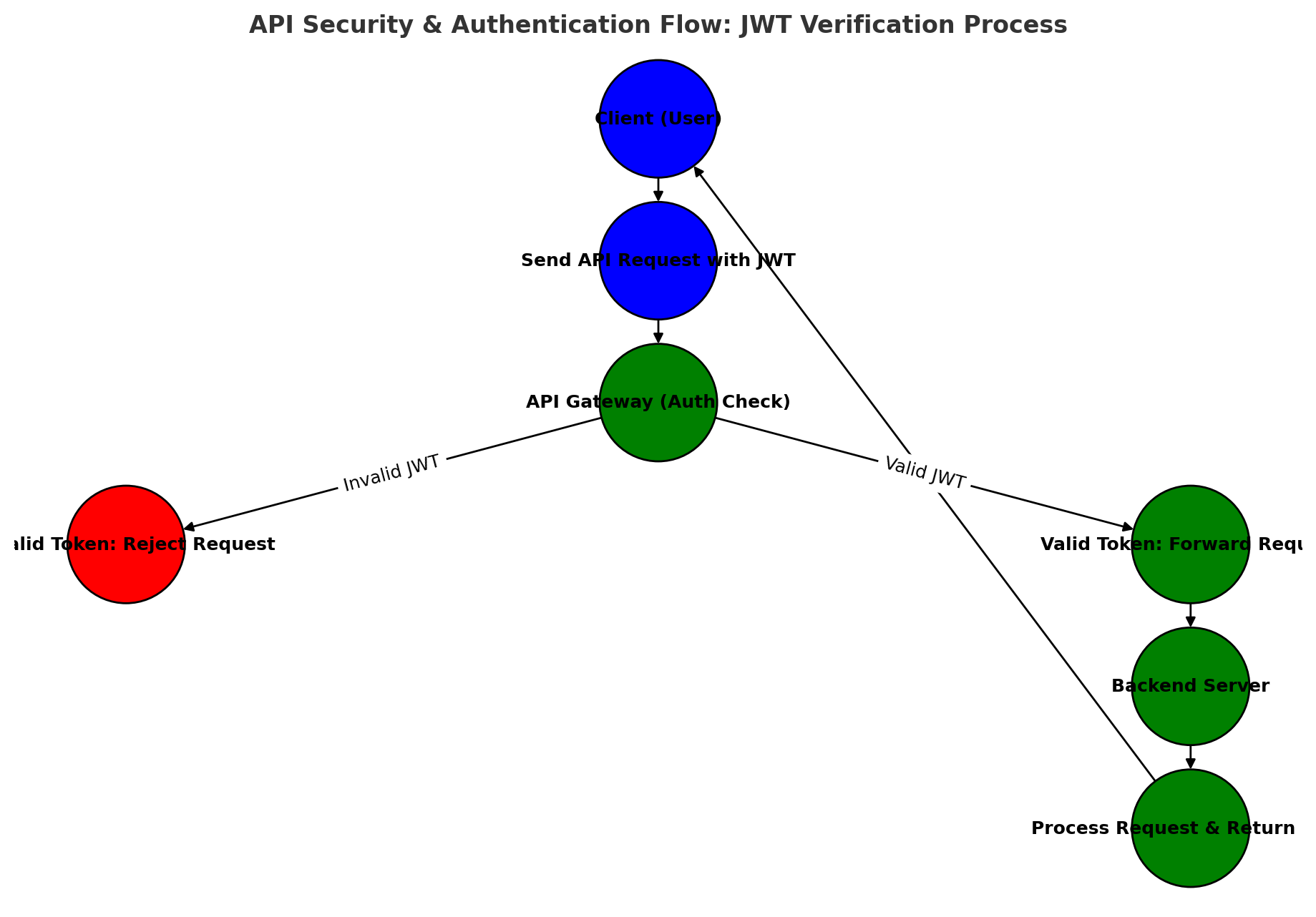
7.3 Scaling for High Availability and Performance
Info: Choosing between vertical and horizontal scaling depends on the system’s growth trajectory—vertical scaling is simpler, while horizontal scaling provides better long-term scalability.
Database Scaling Techniques
| Scaling Method | Purpose |
|---|---|
| Read Replication | Improves read performance, offloads queries from primary database |
| Sharding | Distributes large datasets across multiple servers |
| Partitioning | Splits data across storage for faster queries |
| Load Balancing | Distributes database requests evenly across nodes |
Horizontal vs. Vertical Scaling
| Scaling Type | Approach | Pros | Cons |
|---|---|---|---|
| Vertical Scaling (Scaling Up) | Add CPU/RAM to a single server | Simpler setup | Limited by hardware |
| Horizontal Scaling (Scaling Out) | Add more servers (distributed DBs) | High availability & redundancy | More complex |
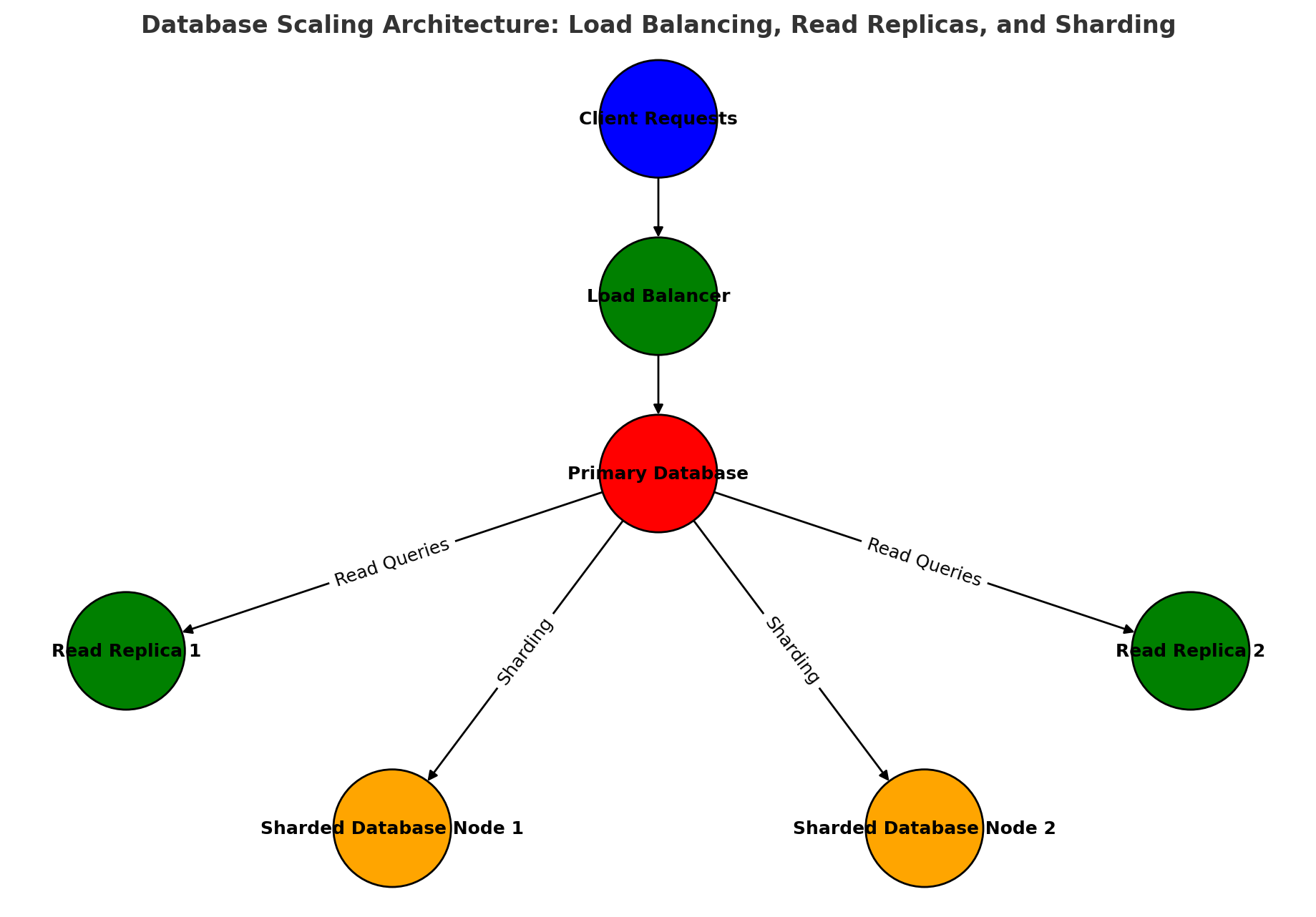
Tip: Read replicas are ideal for offloading read-heavy workloads, improving performance, and reducing the load on the primary database.
Example: Setting Up Read Replicas for High Traffic
1
CREATE REPLICA REPLICA_1 FROM MAIN_DATABASE;
Read replicas allow high-frequency account balance queries without overloading the primary database.
Using Load Balancers for Distributed Transactions
- Use Nginx or AWS ALB to distribute API requests across multiple backend instances.
- Implement failover mechanisms to reroute traffic in case of a database node failure.
Example: Configuring Load Balancer for API Requests
1
2
3
4
upstream backend_servers {
server app1.example.com;
server app2.example.com;
}
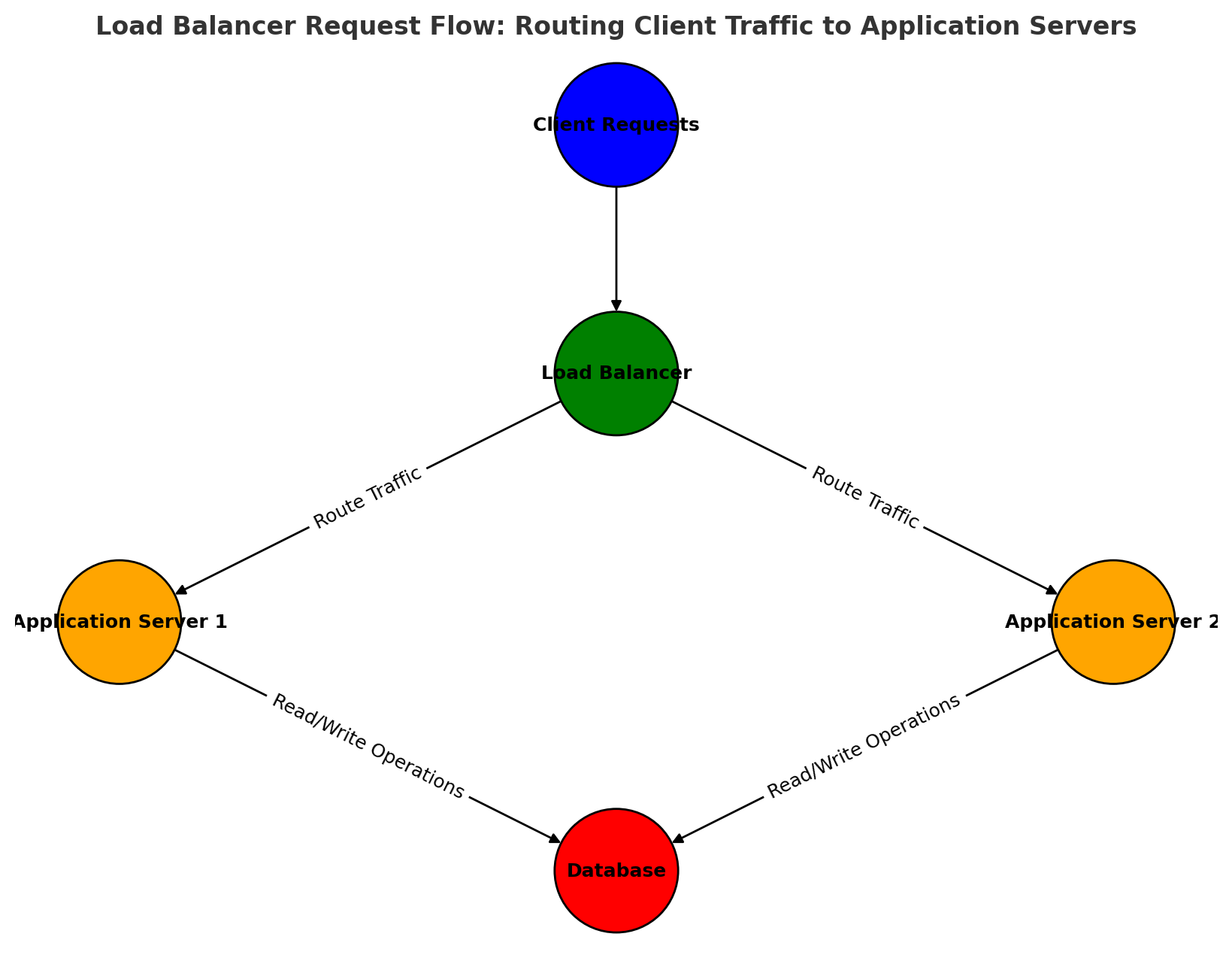
7.4 High Availability & Disaster Recovery
Info: Automated failover mechanisms ensure minimal downtime by switching to a standby database in case of primary database failure.
Failover & Redundancy
- Deploy active-passive failover databases to switch in case of failure.
- Use automated backups & point-in-time recovery (PITR) for data protection.
Example: Enabling Point-in-Time Recovery (PITR) in PostgreSQL
1
ALTER SYSTEM SET wal_level = 'logical';
Tip: Store database backups in geographically distributed locations to protect against regional outages and disasters.
Disaster Recovery Strategy
- Regular backups stored in geo-redundant storage.
- Automated failover mechanisms for minimal downtime.
- Chaos testing to simulate failures and ensure resilience.
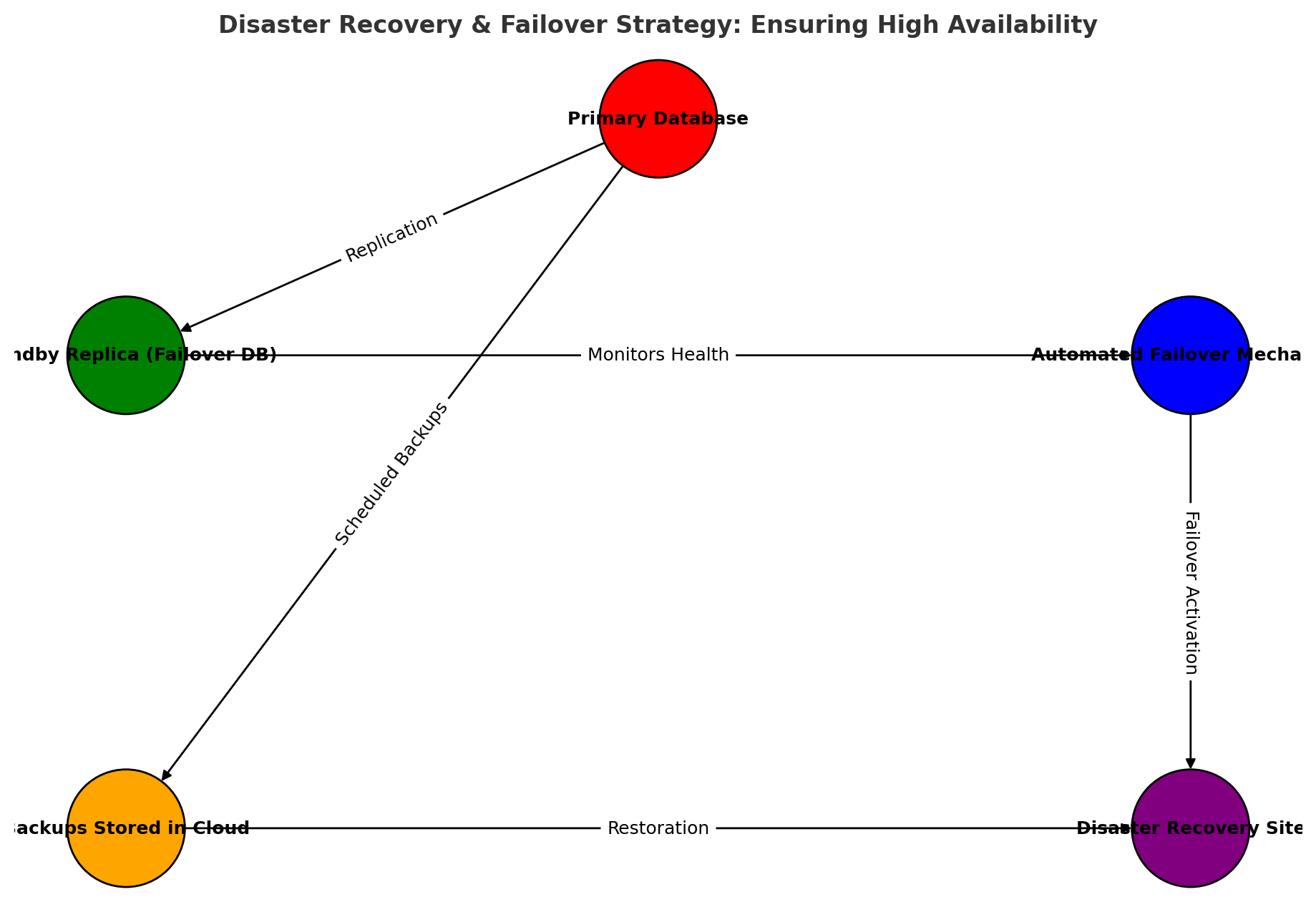
Section 8: Deployment, Monitoring, and Future Enhancements
Deploying a banking ledger system requires a secure, scalable, and well-monitored infrastructure to ensure high availability and compliance with financial regulations.
This section covers:
- Production deployment strategies to ensure security and efficiency
- Monitoring and logging for system performance and security auditing
- Future enhancements to improve scalability, security, and resilience
8.1 Secure and Scalable Deployment Strategies
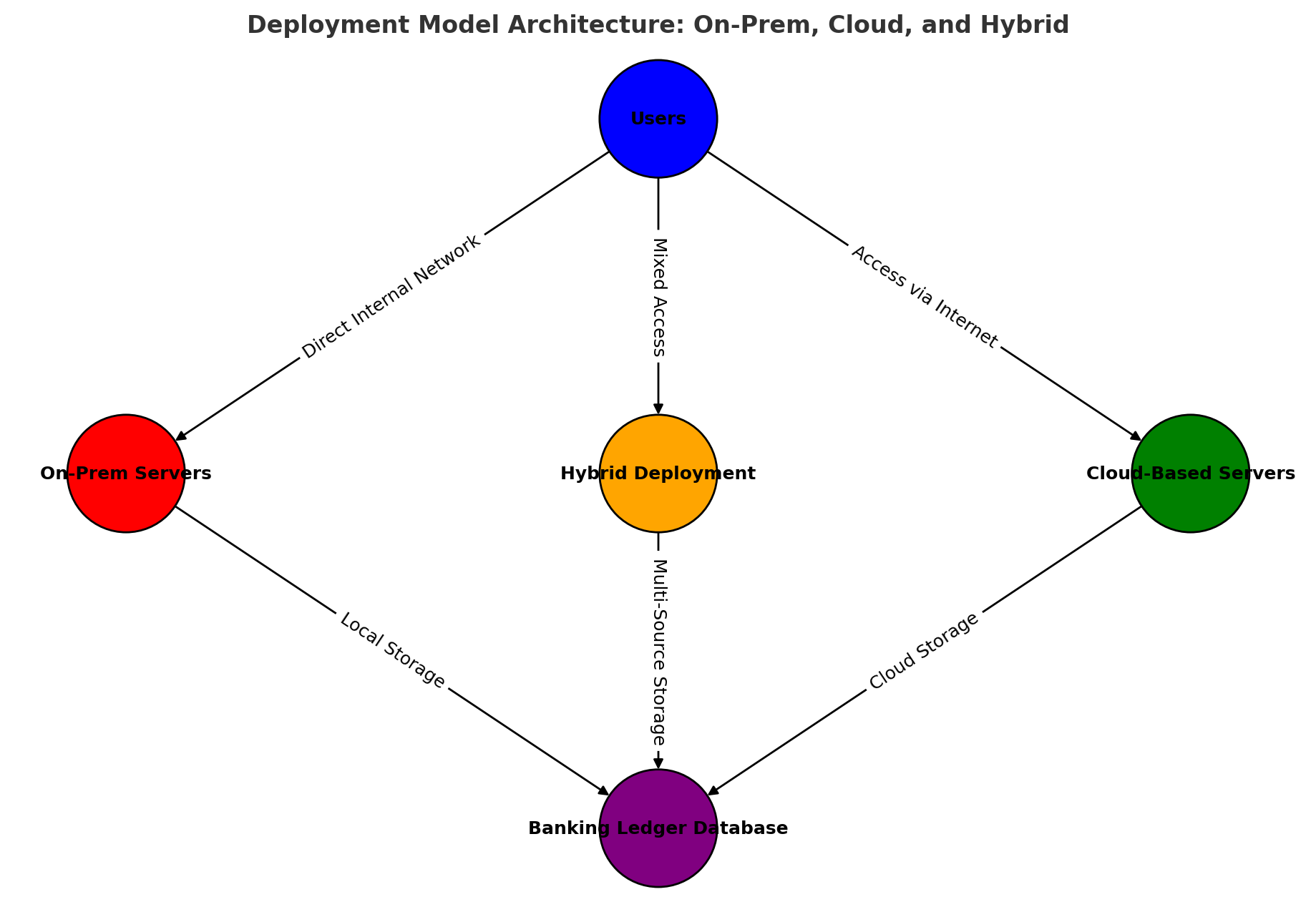
Choosing the Right Deployment Model
A banking ledger system can be deployed in different environments, each with its own advantages:
| Deployment Model | Advantages | Disadvantages |
|---|---|---|
| On-Premises | Full control over infrastructure, better regulatory compliance | High maintenance cost, limited scalability |
| Cloud-Based (AWS, Azure, GCP) | High scalability, managed security, cost efficiency | Dependent on cloud provider, requires strong IAM policies |
| Hybrid (On-Prem + Cloud) | Best of both worlds, flexibility | More complex to manage, requires integration expertise |
Tip: A hybrid approach allows organizations to keep sensitive financial data on-premises while leveraging cloud scalability for high-traffic workloads.
Deployment Model Architecture
This diagram illustrates the differences between On-Premises, Cloud-Based, and Hybrid deployment strategies for the banking ledger system.
Infrastructure as Code (IaC) Workflow
Using Infrastructure as Code (IaC) ensures a repeatable, automated deployment process, reducing manual errors.
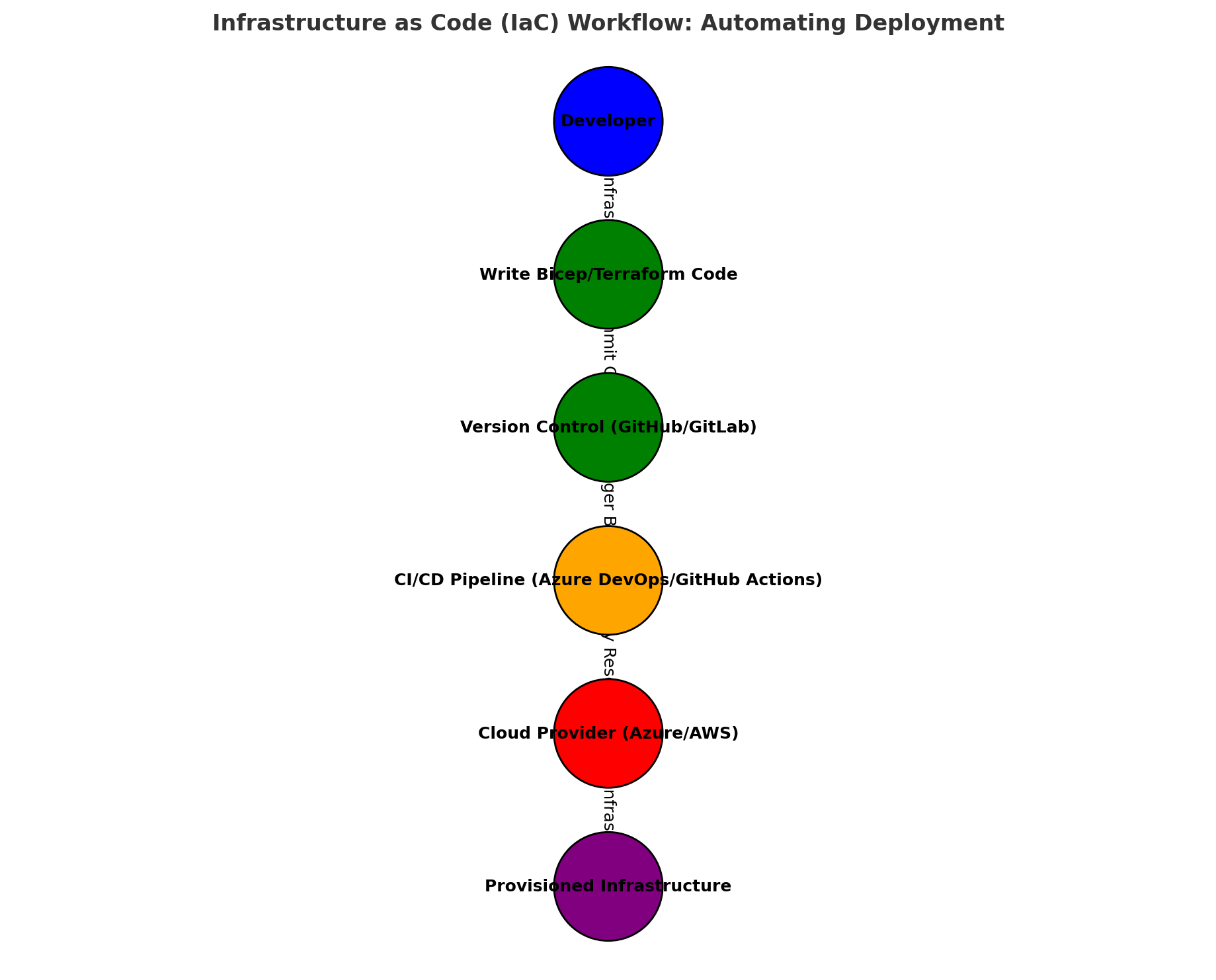
Infrastructure as Code (IaC) for Deployment
Using Infrastructure as Code (IaC) automates deployment, reducing manual errors and ensuring repeatability. Bicep or Terraform can be used to define cloud infrastructure for the banking ledger system.
Example: Deploying an Azure SQL Database using Bicep
resource bankingDb 'Microsoft.Sql/servers/databases@2021-02-01-preview' = {
name: 'BankingLedgerDB'
location: resourceGroup().location
properties: {
collation: 'SQL_Latin1_General_CP1_CI_AS'
maxSizeBytes: 2147483648
}
}
Info: Using Infrastructure as Code (IaC) ensures a consistent and automated deployment process, reducing human errors in production.
Database Migration & Version Control
- Use Flyway or Liquibase for database version control
- Implement Zero-Downtime Deployment to avoid service disruptions
- Perform Schema Migrations incrementally and validate changes in staging before production
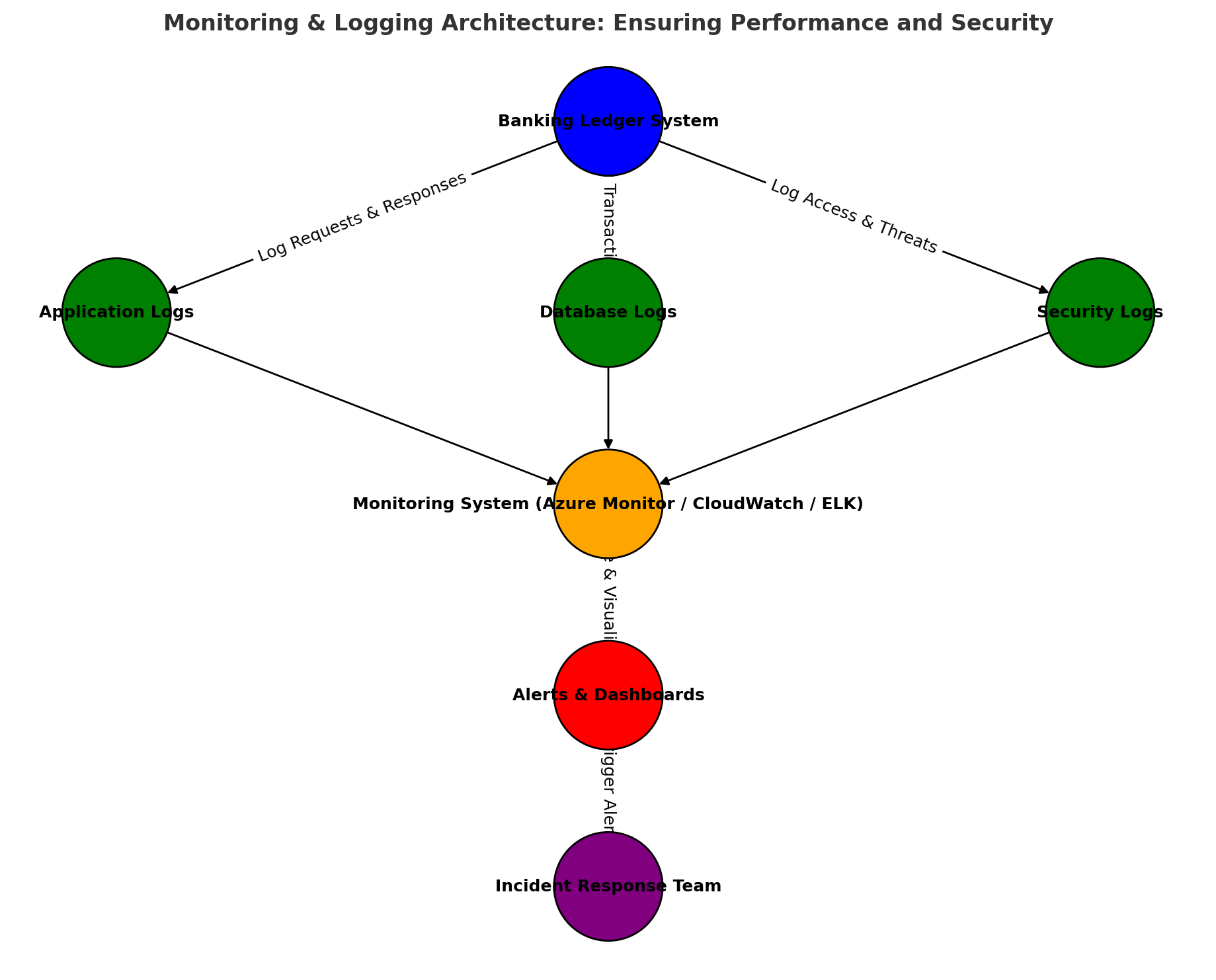
8.2 Monitoring and Logging for Performance & Security
Key Metrics to Monitor
A well-monitored banking ledger system helps detect performance issues, security threats, and anomalies. Critical metrics include:
| Metric | Purpose |
|---|---|
| Database Query Latency | Detects slow queries affecting transaction speed |
| Transaction Success Rate | Monitors failed vs. successful transactions |
| API Response Time | Ensures APIs remain responsive for end-users |
| Error Logs & Security Audits | Detects unauthorized access attempts |
| Disk Usage & Replication Lag | Ensures data availability and synchronization |
Tip: Implement real-time monitoring with alerts to detect abnormal transaction behavior, such as multiple failed withdrawals in a short time.
Logging Best Practices
Logs help in troubleshooting and ensuring compliance with financial regulations.
- Use structured logging (JSON format) for easy querying and analysis
- Store logs in Azure Monitor, AWS CloudWatch, or ELK Stack (Elasticsearch, Logstash, Kibana)
- Implement log retention policies to meet compliance requirements
Example: Logging API Transactions in JSON Format
1
2
3
4
5
6
7
8
{
"timestamp": "2025-03-10T12:00:00Z",
"transaction_id": "TXN123456",
"account_id": "ACC789",
"amount": 500.00,
"status": "SUCCESS",
"response_time_ms": 120
}
Info: Structured logging enables better searchability and integration with monitoring tools like Grafana or Kibana.
Anomaly Detection & Security Auditing
- Implement AI-powered fraud detection to identify unusual transaction patterns
- Enable audit logs to track changes and ensure regulatory compliance
- Use SIEM (Security Information and Event Management) for real-time threat detection
Tip: Integrate SIEM tools like Splunk or Microsoft Sentinel to detect security threats and log anomalies in real-time.
Monitoring & Logging Architecture
This diagram shows how real-time monitoring and logging systems track performance, security, and anomalies in the banking ledger system.
8.3 Future Enhancements and Scalability Improvements
Enhancing System Resilience
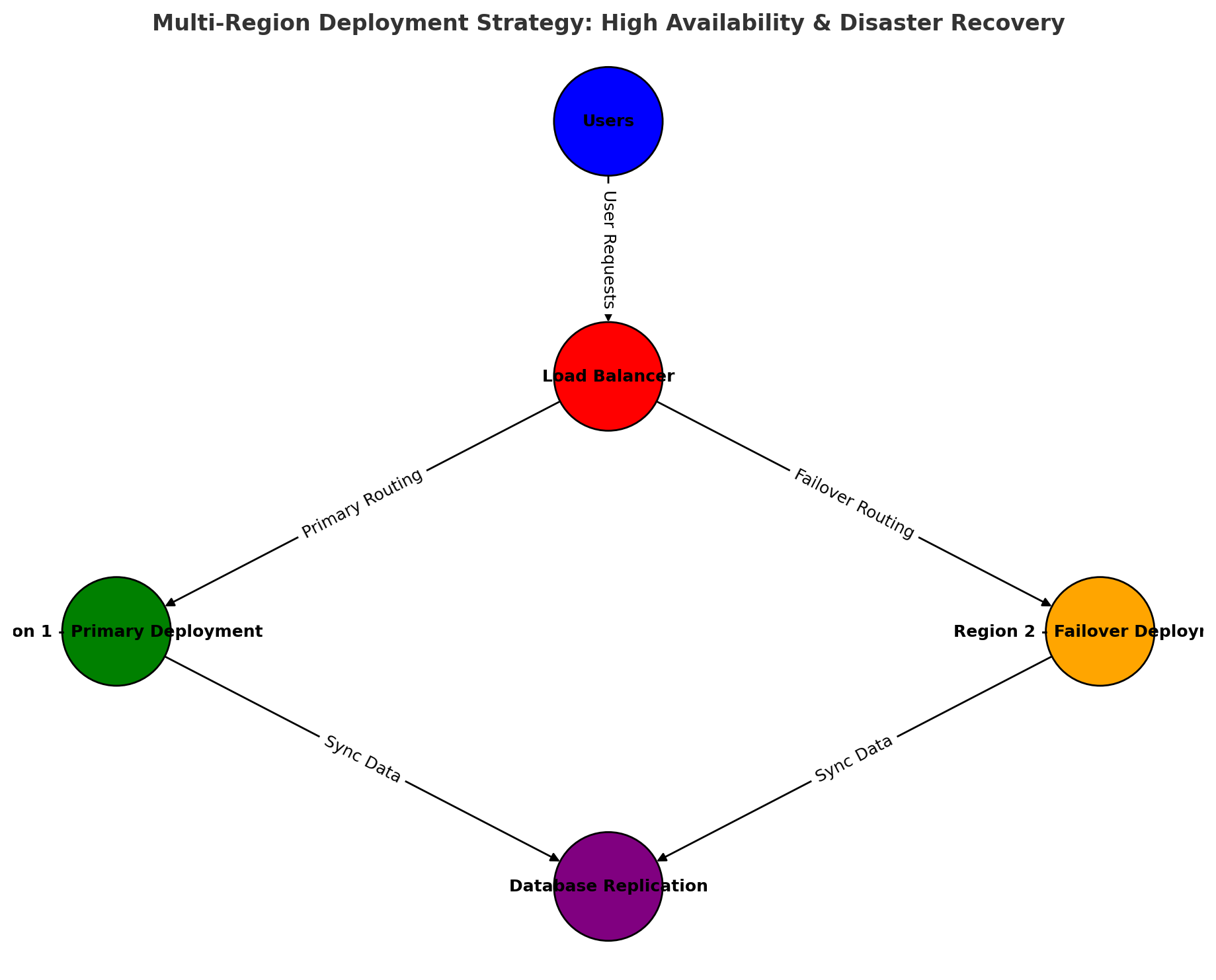
- Multi-Region Deployment – Deploy databases in multiple regions for disaster recovery
- Auto-Scaling – Automatically adjust infrastructure based on demand
- Optimized Data Partitioning – Use range-based sharding for efficient querying
Info: Multi-region deployments reduce downtime and improve availability by providing automatic failover to a secondary region.
Multi-Region Deployment Strategy
This diagram shows how deploying databases and application servers across multiple geographic regions ensures disaster recovery and minimal downtime.
Blockchain Integration for Transaction Transparency
- Immutable Ledger: Blockchain ensures an unalterable record of transactions
- Smart Contracts: Automate compliance rules and fraud detection
- Distributed Consensus: Reduces reliance on a single point of failure
Tip: Blockchain technology can be used to enhance ledger transparency and prevent unauthorized modifications.
AI & Machine Learning for Fraud Prevention
Behavioral Analytics: Detect suspicious activity based on user transaction patterns Automated Risk Scoring: Assign risk levels to transactions in real-time Real-Time Anomaly Detection: Flag unusual transactions for manual review
AI-Powered Fraud Detection
This diagram outlines how machine learning models process transaction patterns to detect fraud and prevent financial crimes.
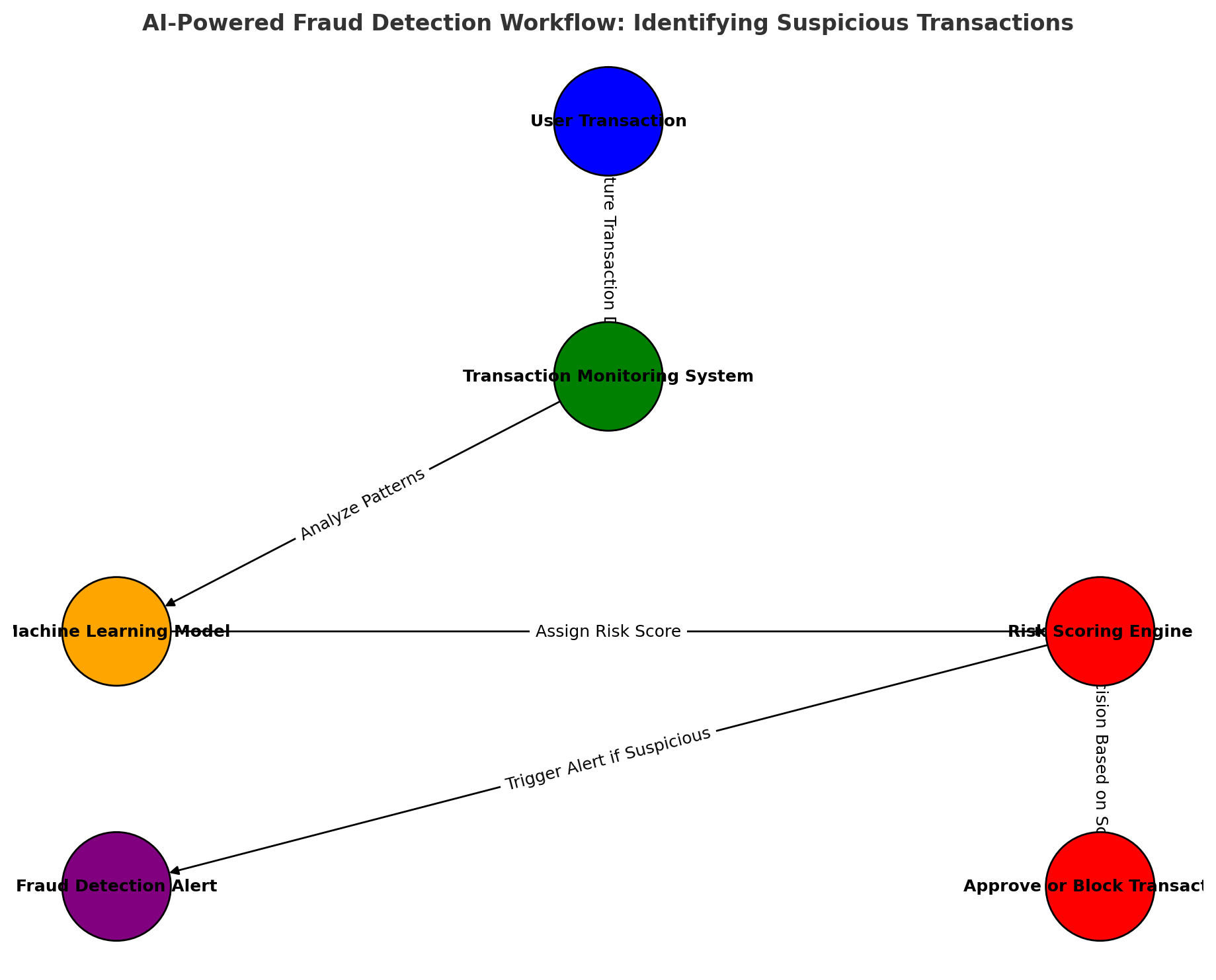
Info: Machine learning models trained on historical transaction data can detect fraud with high accuracy.
Section 9: Conclusion & Key Takeaways
The Banking Ledger System is a critical financial infrastructure that ensures accuracy, security, and scalability in handling transactions. This guide has walked through database architecture, ACID compliance, transaction management, concurrency control, security best practices, and deployment strategies.
This section provides a final summary of key learnings, best practices, and next steps for improving and maintaining a high-performance banking ledger system.
9.1 Key Takeaways
Database Design & ACID Compliance
- ✅ Ensure strong data integrity by enforcing constraints, foreign keys, and unique indexes.
- ✅ ACID transactions prevent financial inconsistencies by ensuring atomicity, consistency, isolation, and durability.
- ✅ Double-entry bookkeeping ensures accountability and prevents financial discrepancies.
Tip: Using strict constraints like
CHECK,UNIQUE, andFOREIGN KEYensures database consistency and prevents invalid transactions.
Transaction Processing & Concurrency Control
- ✅ Isolation levels prevent anomalies (dirty reads, non-repeatable reads, phantom reads).
- ✅ Pessimistic locking is best for high-value transactions, while optimistic locking suits high-read workloads.
- ✅ Deadlock handling & timeout strategies prevent stalled transactions.
Info: Choosing the right isolation level balances data consistency and performance. Use
SERIALIZABLEfor strict accuracy andREAD COMMITTEDfor performance.
Security & Fraud Prevention
- ✅ Encrypt sensitive data at rest and in transit to protect financial records.
- ✅ Implement multi-factor authentication (MFA) and role-based access control (RBAC) for user security.
- ✅ Use AI-powered fraud detection to flag suspicious transactions.
Tip: Log all security events and use AI-driven anomaly detection to identify fraudulent activity in real time.
Scalability & High Availability
- ✅ Use read replicas & database sharding to handle large transaction volumes.
- ✅ Deploy across multiple regions to ensure high availability and disaster recovery.
- ✅ Automate infrastructure with Infrastructure as Code (IaC) to improve consistency.
Info: Multi-region deployments improve fault tolerance and prevent data loss in case of server failures.
9.2 Best Practices for Long-Term Maintenance
Regular Database Optimization: Use indexing, query optimization, and partitioning to maintain fast performance.
- Continuous Security Audits: Conduct vulnerability assessments and penetration testing to detect potential weaknesses.
- Automated Backups & Disaster Recovery: Store encrypted backups in multiple locations and conduct failover drills.
- Compliance & Regulatory Adherence: Ensure the system meets financial regulations (PCI-DSS, GDPR, SOC 2).
Tip: Set up real-time monitoring alerts to detect abnormal database activity and potential performance bottlenecks.
9.3 Future Enhancements & Next Steps
To stay ahead in the evolving financial technology landscape, consider these enhancements:
- 🔹 Blockchain Integration: Implement immutable ledgers for transaction transparency.
- 🔹 Real-time AI Fraud Detection: Improve fraud detection with predictive analytics & machine learning.
- 🔹 Serverless & Cloud-Native Architectures: Reduce costs and enhance scalability with serverless computing (Azure Functions, AWS Lambda).
Info: Using AI for fraud detection and blockchain for financial security can significantly improve transaction trustworthiness.
Final Thoughts
Building a scalable, secure, and reliable banking ledger system requires strong database design, optimized transaction processing, robust security, and high-availability deployment strategies.
By following best practices in data integrity, concurrency control, security, and cloud scalability, organizations can ensure financial accuracy, prevent fraud, and deliver a seamless user experience.
Resources & Further Reading
This section provides official documentation and authoritative references on key topics covered in this paper, including database management, security best practices, cloud deployments, and fraud detection methodologies.
1. Database Management & ACID Compliance
Ensuring data integrity, transaction reliability, and performance optimization is fundamental in banking systems. The following resources provide official guidelines on ACID compliance, indexing, and concurrency control.
PostgreSQL ACID Compliance & Transactions
PostgreSQL’s official documentation on transaction isolation, locking mechanisms, and durability.
URL: https://www.postgresql.org/docs/current/transaction-iso.htmlMySQL InnoDB: ACID Transactions & Isolation Levels
A deep dive into ACID compliance and concurrency control in MySQL’s InnoDB storage engine.
URL: https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-model.htmlMicrosoft SQL Server Transactions & Locking
Official guide on SQL Server isolation levels, deadlocks, and transaction handling.
URL: https://learn.microsoft.com/en-us/sql/t-sql/statements/set-transaction-isolation-level-transact-sql
2. Security & Compliance in Banking Systems
Financial transactions must be secure, encrypted, and compliant with global regulations. The following resources outline best practices for data security, encryption, and compliance.
NIST Cybersecurity Framework (CSF) for Financial Services
The National Institute of Standards and Technology (NIST) framework for securing financial transactions and sensitive data.
URL: https://www.nist.gov/cyberframeworkOWASP Security Best Practices for Web Applications
Comprehensive guidelines for securing APIs, preventing SQL injection, and implementing access control.
URL: https://owasp.org/www-project-top-ten/PCI DSS Compliance for Banking Transactions
The official Payment Card Industry Data Security Standard (PCI DSS) for handling financial transactions securely.
URL: https://www.pcisecuritystandards.org/documents/PCI_DSS_v4.pdf
3. Cloud Infrastructure & Deployment
Cloud platforms enable scalable, high-availability banking systems. The following resources provide official documentation on cloud deployments, monitoring, and automation.
Azure API Management & Security Best Practices
Microsoft’s guide to securing and optimizing API management in cloud-based banking systems.
URL: https://learn.microsoft.com/en-us/azure/api-management/AWS Well-Architected Framework for Financial Services
Amazon’s best practices for building scalable, resilient, and secure cloud-based financial applications.
URL: https://docs.aws.amazon.com/wellarchitected/latest/financial-services-industry-lens/Google Cloud SQL for Scalable Financial Databases
Google Cloud’s official guide for deploying, scaling, and securing SQL databases in a cloud environment.
URL: https://cloud.google.com/sql/docs
4. AI-Powered Fraud Detection & Risk Management
Artificial intelligence enhances fraud detection and risk analysis in banking transactions. The following resources explore machine learning models and AI-driven financial security.
Microsoft AI for Fraud Prevention
Azure’s guide to building AI models for anomaly detection in banking transactions.
URL: https://learn.microsoft.com/en-us/azure/architecture/example-scenario/ai/real-time-fraud-detectionGoogle Cloud AI Fraud Detection Solutions
Google’s official AI-based fraud detection framework for financial transactions.
URL: https://cloud.google.com/solutions/fraud-detectionIBM Watson Financial Fraud Detection
IBM’s machine learning solutions for identifying suspicious banking transactions.
URL: https://www.ibm.com/cloud/financial-crimes-insights
5. Disaster Recovery & High Availability
Ensuring continuous uptime and failover strategies is essential in banking applications. The following resources cover multi-region deployments, failover mechanisms, and cloud DR strategies.
AWS Multi-Region Disaster Recovery Guide
Amazon’s best practices for deploying banking workloads across multiple cloud regions.
URL: https://docs.aws.amazon.com/wellarchitected/latest/reliability-pillar/multi-region-deployments.htmlMicrosoft Azure Site Recovery for Disaster Recovery
Azure’s official documentation on replicating databases and maintaining failover capabilities.
URL: https://learn.microsoft.com/en-us/azure/site-recovery/Google Cloud Disaster Recovery Planning
Google Cloud’s framework for building resilient, highly available financial systems.
URL: https://cloud.google.com/architecture/dr-scenarios-planning
Conclusion
The financial industry demands high-performance, secure, and scalable banking ledger systems. By leveraging database best practices, cloud automation, security frameworks, AI-driven fraud detection, and disaster recovery mechanisms, organizations can build reliable financial applications.
For further research and development, refer to the official documentation linked above.